| |
Oswald
Registered: Apr 2002
Posts: 5017 |
Converting animation into lossy charset - how ?
I've always wondered how an algorithm decides how far is a char from another. any pointers ? |
|
| |
MagerValp
Registered: Dec 2001
Posts: 1055 |
This should be a good starting point: http://stackoverflow.com/questions/613146/computing-the-differe.. |
| |
Krill
Registered: Apr 2002
Posts: 2844 |
You also might want to take a look at how JPEG compression works, which divides the image into 8x8 blocks prior to quantisation: http://www.fileformat.info/mirror/egff/ch09_06.htm.
The resulting image data is then represented in the frequency domain, and those coefficients you can compare and cluster rather easily and prioritise luminance differences over chrominance differences, as the eye is more perceptive to the former. Well, etc.pp. :) |
| |
Oswald
Registered: Apr 2002
Posts: 5017 |
looks like quite a complex topic, FFT is a good idea, but I'd like to think there's a primitive c64 demo way :) fex what if each pixel checks how itself and its 8 neighbours differ from the pixels at the same position in the compared char. |
| |
chatGPZ
Registered: Dec 2001
Posts: 11116 |
why dont you simply try it? with a simple compare function like you say its pretty easy to knock up afterall :) |
| |
Krill
Registered: Apr 2002
Posts: 2844 |
Quoting Oswaldlooks like quite a complex topic, FFT is a good idea, but I'd like to think there's a primitive c64 demo way :) fex what if each pixel checks how itself and its 8 neighbours differ from the pixels at the same position in the compared char. We're talking about pre-processing here, and this has been on a far more complex level than the C-64 can manage for years now, for modern demos. |
| |
Oswald
Registered: Apr 2002
Posts: 5017 |
I'm actually trying :)
Gunnar, yes I know, I'm just lazy to mess with FFT totally new territory for me, altho i know what its basically, but its a totally different thing when you have to code it (or make some alien code to work) |
| |
Mixer
Registered: Apr 2008
Posts: 422 |
Very simple and very lossy system that makes very ugly pictures.
Make a random charset. Randomize it so that first char has 0 pixels set and last char has all pixels set. Second char has 1 random pixel set etc.
Count the set pixels in the char-area of the source image and replace the char with random char that has equal number of pixels set. This is like calculating the average luminocity over the char-area and matching it with charset.
One can go to many directions with this, for instance, the random charset generated don't need to be "linearly random". Also, once the image is matched to the noise charset, one can locate where each noise char is used and compare original image regions on those locations as more accurate 4x4 pixel luminosities, and alter the 8x8 noise charset quarters if a part of them is similar enough and iterate. |
| |
Oswald
Registered: Apr 2002
Posts: 5017 |
macthing against char rom now, prototype fills the destination currently with 'N' :) more to debug.. |
| |
4mat
Registered: May 2010
Posts: 63 |
I think my petscii converter does a simple tally per 8x8 grid against the char rom, then picks the highest scoring char. Good thing is if you use a custom char set it'll always pick something regardless of the size. (in Party Bit the credit pictures were done with a 6 char font) Doing colour pics was a bit more involved, I went with a threshold level around the rgb values in the pic and compared against the palette's rgb. (Probably should have used luminance as well but I didn't) |
| |
Krill
Registered: Apr 2002
Posts: 2844 |
Quoting 4matI think my petscii converter does a simple tally per 8x8 grid against the char rom, then picks the highest scoring char. Good thing is if you use a custom char set it'll always pick something regardless of the size. Matching against an existing set of chars makes the problem a lot easier, i think. Generating an "optimal" set of arbitrary chars, on the other hand... :) |
| |
Krill
Registered: Apr 2002
Posts: 2844 |
Quoting OswaldI'm just lazy to mess with FFT totally new territory for me, altho i know what its basically, but its a totally different thing when you have to code it (or make some alien code to work) Actually, playing around with libjpeg for this purpose and maybe hacking it to produce 256 characters doesn't sound like a half-bad idea to me.
Groepaz, what's your verdict? And algorithm, please do tell us some details of what you did so far! :) |
| |
algorithm
Registered: May 2002
Posts: 702 |
I wont post everything here. But for a quick insight into the basics of what I am doing. please read the manual of one of my tools here
https://www.dropbox.com/s/ygmfp8nd0o4z35m/CSAM%20Super%20-%20Ma.. |
| |
chatGPZ
Registered: Dec 2001
Posts: 11116 |
Quote:Groepaz, what's your verdict?
i have not yet seen anything lossy on C64 that i liked (sorry algo) and i dont think i can make it better either :) (and i dont find it an interesting subject in the first place) |
| |
ChristopherJam
Registered: Aug 2004
Posts: 1378 |
FWIW, both the zoomer in Effluvium and the animated ball in Jam Ball 2 use variations on k-means clustering, with a fair amount of tweaking.
Basics are explained at https://en.wikipedia.org/wiki/K-means_clustering where each observation X corresponds to an 8x8 tile from one of the source images. (or, in Effluvium's case, an L shaped tile that covers three chars..)
I tend to work in greyscale until I have a decent dictionary, then dither that to hires or multicolor before requantising the frames to the final character set. For Jam Ball 2 I actually built dictionary of somewhere around 260-265 entries, as several of the final entries merged once I dropped to one bit per pixel.
A JPEG style DCT means you can start with comparing overall luminance and low frequency components, but really that's mostly a speed optimisation. A simple sum of squared differences works pretty well, and at one bit per pixel that turns out to just be a count of the pixels that are different. |
| |
JackAsser
Registered: Jun 2002
Posts: 1989 |
Oswald: The technique is called clustering. The algorithm below is naive and extremely slow. Finding the optimal solution is NP-complete. You need to cut corners, but just to give you an idea:
1) Generate all possible chars the animation has. It can be millions depending on how long it is etc.
2) You need to keep track of the frequencies, i.e. how often is a particular char used.
3) You need to create a function which calculate the difference between two characters and give a score. 0 == equal. >0 != equal. A method could be using least squares (https://en.wikipedia.org/wiki/Least_squares) or so.
4) Loop until your charset is x characters long.
4.1) Find all character pairs.
4.2) Generate an intermediate char. F.e. by averaging the two, or so.
4.3) Calculate the visual impact if you should pick that intermediate char by looking up in your frequency tables.
4.4) Pick the pair with the lowest possible visual impact and replace the two source chars with the intermediate char. Delete the source chars from the charset and update the frequencies.
Eon later you will have your clustered charset. This is how the rotator work in Mekanix. How the horizontal twister in Amplifire work etc. |
| |
Oswald
Registered: Apr 2002
Posts: 5017 |
suprisingly good considering it basically only counts and compares set pixels yet.
 |
| |
Oswald
Registered: Apr 2002
Posts: 5017 |
holy cow, least squares and k-means makes me wanna code FFT. respect guys you can understand and implement that :) |
| |
Oswald
Registered: Apr 2002
Posts: 5017 |
another bug ironed, quite puzzling, I only compare pixels at te same place, if not distance = +1. the result is much better than expected.
 |
| |
Oswald
Registered: Apr 2002
Posts: 5017 |
for comparison with previous
 |
| |
JackAsser
Registered: Jun 2002
Posts: 1989 |
Now make a new Goa Brudbilder 2! :D |
| |
Oswald
Registered: Apr 2002
Posts: 5017 |
lol no, thats eye cancer :) actually the nice rotation anim inspired me in the new hoaxers reu demo.
couldnt google anything usable for my simple mind in pattern matching, anyone ? :) |
| |
Marq
Registered: Sep 2011
Posts: 47 |
I did some similar stuff for the Sharp MZ-700, which only has a fixed charset. One little addition that helped especially with lines was to test against chars that had been shifted up/down/left/right one pixel.
 |
| |
LHS
Registered: Dec 2002
Posts: 66 |
A really primitive unscientific brute force method used in my converter to compare two chars:
chb1 = first Byte from char1
chb2 = first Byte from char2
res_and = chb1 AND chb2
res_or = chb1 OR chb2
sum1 = sum of bits in res_and
sum2 = sum of bits in res_or
Compare sum1 and sum2. The higher difference means dissimilarity. If = 0, the Bytes are equal, 1 is very similar, 8 is totally dissimilar...
Compare all Bytes in two chars and sum all results (in ABS values). |
| |
Oswald
Registered: Apr 2002
Posts: 5017 |
LHS, that sounds like what I do, but more complicated: compare bits on all 64 locations, and count differences.
your method: fex we have a set bit (1) and a cleared bit (0) on the same location
1 and 0 = 0
1 or 0 = 1
different bits: 1
1 and 1 = 1
1 or 1 = 1
different bits: 0 |
| |
ChristopherJam
Registered: Aug 2004
Posts: 1378 |
Optimising a little,
sum2 - sum1 will always be equal to the sum of bits in (chb1 XOR chb2) |
| |
LHS
Registered: Dec 2002
Posts: 66 |
That's right, XOR gives directly sum of different bites... |
| |
JackAsser
Registered: Jun 2002
Posts: 1989 |
@Oswald: You might wanna check out the endless guru-zoomer in Sharp |
| |
Bitbreaker
Registered: Oct 2002
Posts: 500 |
I used ELBG for creating an optimal charset, downsampling to c64 colours + dithering should happen after optimal charset was found. For PETSCII however the simple approach was enough so far, but one might restrict the chars being used to have a more graphical appearance without too many letters being used. |
| |
Oswald
Registered: Apr 2002
Posts: 5017 |
Quote: @Oswald: You might wanna check out the endless guru-zoomer in Sharp
I'd rather check out a least squares method in pseudo code for a 8x8 matrix :) |
| |
Oswald
Registered: Apr 2002
Posts: 5017 |
Quote: I used ELBG for creating an optimal charset, downsampling to c64 colours + dithering should happen after optimal charset was found. For PETSCII however the simple approach was enough so far, but one might restrict the chars being used to have a more graphical appearance without too many letters being used.
okay guys how do you manage to implement those algorithms, its all cryptic to me at Wikipedia. Maybe its my non existant university degree ? I saw in some places partial derivation and shit like that, totally over the top of my head.
- downsampling to c64 colors before dithering ?
- simple method = counting different bits on same loc ? why would one need a better one if character set is not fixed ? |
| |
JackAsser
Registered: Jun 2002
Posts: 1989 |
Quote: okay guys how do you manage to implement those algorithms, its all cryptic to me at Wikipedia. Maybe its my non existant university degree ? I saw in some places partial derivation and shit like that, totally over the top of my head.
- downsampling to c64 colors before dithering ?
- simple method = counting different bits on same loc ? why would one need a better one if character set is not fixed ?
Why you need a better version?
Imagine you want:
0001
0011
0111
1111
but you only have these two:
0001 1001
0111 1011
1111 0111
1111 1111
Both have 2 pixels wrong, which one appeals to you most? |
| |
Oswald
Registered: Apr 2002
Posts: 5017 |
finally an example which shows that my "gut feeling" method would be better than bit counting. ie: check the 9 pixels around each pixel. some weighing may help, more for the middle, bit less for the diagonals than for the ortogonals. |
| |
JackAsser
Registered: Jun 2002
Posts: 1989 |
Quote: finally an example which shows that my "gut feeling" method would be better than bit counting. ie: check the 9 pixels around each pixel. some weighing may help, more for the middle, bit less for the diagonals than for the ortogonals.
This problem generally falls into a domain called pattern matching. Don't forget to weight your selection agains the frequency of the chars. F.e. the screen might be covered by a background char used in 75% of all screen positions. This char is much more important to get right, than a char seldom used. It all boils down to choosing in a way to fool the human brain, especially when you start doing multicolour and gradient, when f.e. luminosity is much more important than actual color. |
| |
Oswald
Registered: Apr 2002
Posts: 5017 |
I've googled hours by now on this but no consumable finds for me, I dont know enough to turn wikipedia or papers into code of this subject.
nice pointer with the frequency tho, thanks :)
btw I always tought the mekanix rotator (chess?) is made of an ordered set. this makes it twice as cool. |
| |
Bitbreaker
Registered: Oct 2002
Posts: 500 |
Quoting Oswaldokay guys how do you manage to implement those algorithms, its all cryptic to me at Wikipedia. Maybe its my non existant university degree ? I saw in some places partial derivation and shit like that, totally over the top of my head.
- downsampling to c64 colors before dithering ?
- simple method = counting different bits on same loc ? why would one need a better one if character set is not fixed ?
Downsampling in the meaning of reducing a RGB pic to 4 colors charset + dithering. Or interlaced charsets and alike. As for ELBG, it is implemened in ffmpeg/libav. I just wrote a codec to be plugged into ffmpeg and you then can easily use teh elbg implementation form ffmpeg, as well as read all kind of videpo and picture formats as input without any further effort.
I have a degree, but not in computer science. That does not count :-) |
| |
ChristopherJam
Registered: Aug 2004
Posts: 1378 |
OK, hope this python script is a little more digestible than wikipedia. Code's not as tidy as it would have been if I'd used numpy array operations instead of looping over indices, but hopefully it's a little clearer what's going on this way. It's pretty naive and has plenty of scope for improvement, but should demonstrate the basic principles.
from random import randint
w,h=64,32
pixels=[[int(((x-25)**2+(y-18)**2)**.5/4)%2 for x in range(w)]for y in range(h)]
for row in pixels:
print(" ".join(['.@'[x] for x in row]))
tiles=[[pixels[k//(w//8)*8+j//8][k%(w//8)*8+j%8] for j in range(64)] for k in range(w*h//64)]
num_tiles=len(tiles)
cset_size=20
charset=[]
indices=[]
for i in range(cset_size):
charset.append(tiles[randint(0,len(tiles)-1)])
last_error=1e33
for iteration in range(10):
# first, find indices
indices=[]
counts=[0,]*cset_size
error_this_iteration=0
for i in range(num_tiles):
best_error=1e30
for j in range(cset_size):
this_error=0
for p in range(64):
delta=(tiles[i][p]-charset[j][p])
this_error+=delta*delta
if this_error<best_error:
best_error=this_error
best_index=j
error_this_iteration+=best_error
indices.append(best_index)
counts[best_index]+=1
print"total error =",error_this_iteration
if error_this_iteration==last_error:
break
last_error=error_this_iteration
#then, replace each char with the average of all the source tiles it's meant to approximate
charset=[[0 for i in range(64)] for j in range(cset_size)]
for i in range(num_tiles):
index=indices[i]
for p in range(64):
charset[index][p]+=float(tiles[i][p])/counts[index]
#..and replace any unused chars with random selections from the original
for i in range(cset_size):
if counts[i]==0:
charset[i]=(tiles[randint(0,len(tiles)-1)])
print("")
for y in range(h):
for x in range(w):
i=indices[y//8*(w//8)+x//8]
print ".@"[int(0.5+charset[i][(y%8)*8+(x%8)])],
print
(my degree's in Engineering, but I did do some CS units..) |
| |
Mixer
Registered: Apr 2008
Posts: 422 |
Quote:I have a degree, but not in computer science. That does not count :-)
"partial derivative"-stuff -> trick is to find the code example for all the math notated stuff. Everyone can understand code, very few understand math notation.
<offtopic rant>
I've done CS-major studies and some math and in my opinion the best representation of an algorithm is a code example. The mathematical notation used in academia has almost zero practical value. It is a notation for mathematicians and researchers so that they can prove a point. In comparison to that the code example shows the steps that even the mathematician has to take in order to calculate the result.
Also, the math notation is not supported by most charsets anyway and one has to write latex-code or similar coding anyway to show those characters. Not very practical in that sense either. It is too late to stop that train in academia, though. The academia is too deep in that shit already.
</end rant> |
| |
Oswald
Registered: Apr 2002
Posts: 5017 |
thanks a lot, totally readable :) |
| |
chatGPZ
Registered: Dec 2001
Posts: 11116 |
indeed indeed. i always explicitly try to find code examples, the math nerds at wikipedia even manage to make simple stuff like projectile parabola look super complicated =) |
| |
Oswald
Registered: Apr 2002
Posts: 5017 |
also tried to google for code but no luck.. best was some mathlab stuff which seemed to rely too much on built in functions |
| |
Trash
Registered: Jan 2002
Posts: 122 |
Quote: also tried to google for code but no luck.. best was some mathlab stuff which seemed to rely too much on built in functions
I got curious of this thread and decided to look for samplecode but took another route on finding it i think. There are a great deal of ASCII-demos out there with sourcecode that generates 320x200 images and converts them to ASCII-art according to a friend. I am still looking but I guess (hoping) its the same stuff you are curious about (both math and codewise)... |
| |
Oswald
Registered: Apr 2002
Posts: 5017 |
so how about a pattern matching compo? I'm wondering how much better a more sophisticate algo does than my naive one. Anyone can show his? (penis:)
I've added that each pixel checks its surroundings and weighing (which doesnt seem do shit), only slightly better than counting non matching pixesl.

imho it missreads a lot of features of the original like the inverse ( on the head etc. there's a lot
original pic:
 |
| |
algorithm
Registered: May 2002
Posts: 702 |
just some basics here
select 256 random 8x8 char blocks from the source image/frames
for each block in the original, find the closest match in the 256 random entries and place these together. repeat until all blocks are read
merge the entries. repeat the above steps a few times.
The above is the basics of LBG. Now what you will find more than likely are orphan codebooks where the blocks in the source did not pair up. ELBG solves this issue by reassignment.
Another alternative after this process is to refine the entries after the lbg via hill climbing/genetic methods (as used in CSAM)
This also operates in quarter block and half block regions mapping over to the closest edges of a codebook (instead of forcing to merge the whole block)
Weighting is a must where specific source areas of the image/frames are focused on more/less than others.
There was a good point from Marq where he mentioned shifting some entries before comparison. For example a negative chequerboard and positive one look identical, but when performing a distance check, it would give the worst error ratio. Alternates to the shifting method is to transform the blocks via DCT/FFT and compare
Overall, its not really a nice way of packing data but it is certainly VERY ideal for the c64's tile mode (very fast)
Preprocessing of the animation frames also helps via attempting to keep slightly variated blocks static or some blurring of hard edges.
If ram space is limited, can transform each codevector in many ways xflip,yflip, luminance adjust, although it would use more ram for the buffer (and operate in bitmap mode usually) but speedups can be gained by adjusting only blocks that changed since the last update to that buffer (by keeping the reference recreated lookups)
if dealing with non quantized data, use slightly higher codebook entries (280 etc) as Christopher jam mentioned (this would then more than likely be reduced with some duplicates due to quantization. Alternatively quantize the data first, although mileage may vary and the merging is also less efficient. |
| |
Oswald
Registered: Apr 2002
Posts: 5017 |
thanks, ATMO I'm concentrating on pattern matching, anything on that? can you do a fast CSAM with rom cset on the pic above? :) |
| |
Marq
Registered: Sep 2011
Posts: 47 |
PETSCII editor's brutal built-in converter (just simple pixel matching IIRC):

Kinda lousy, but it's there as a semi-useless add-on anyway :) |
| |
algorithm
Registered: May 2002
Posts: 702 |
Via predefined blocks, it gets much more easy to do this. The hard part is generating custom blocks that represent the image as accurately as possible.
I have a tool here on CSDB (BmpToPET) that does this,
Bmp2pet
maybe you can try it with some settings
using CSAM and custom charset I get the below
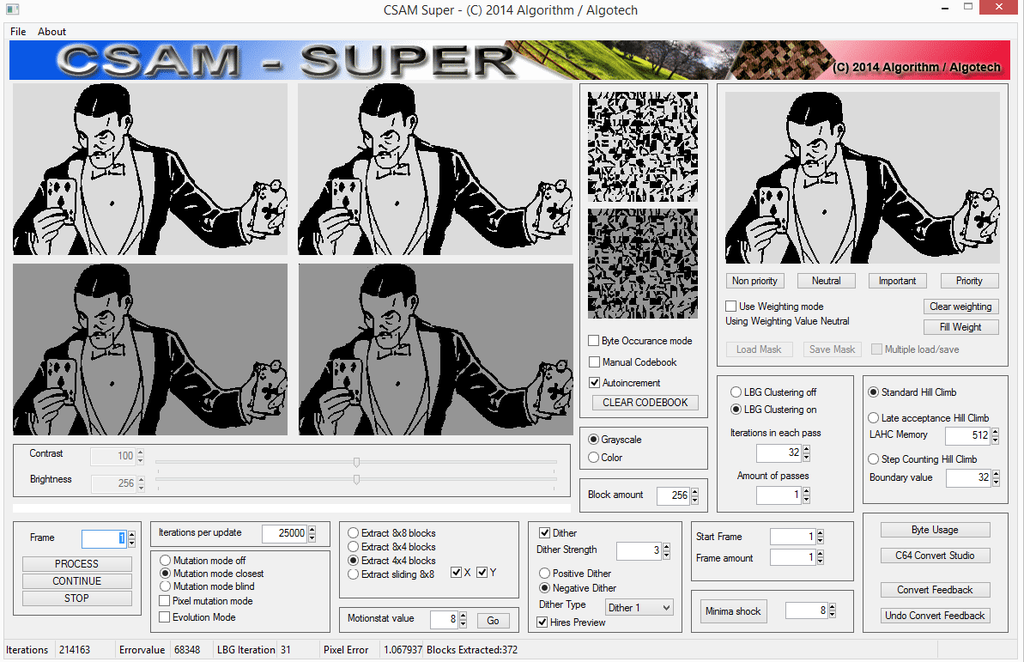 |
| |
Shadow
Account closed
Registered: Apr 2002
Posts: 355 |

Using the converter I wrote when I did my PETSCII version of the Amigaball challenge we had here on the forums a while ago.
Can probably be improved a lot, as it is now it just counts pixels. Will see if I have time to play with it a bit more. |
| |
Oswald
Registered: Apr 2002
Posts: 5017 |
atmo I concentrate on pattern matching, its quite interesting to see how good an algo can match the rom cset against pics :)
will try cross correlation and probably FFT too. |
