| |
Krill
Registered: Apr 2002
Posts: 2856 |
Release id #214940 : TSCrunch
Quoting tonysavon"TSCrunch is an optimal, byte-aligned, LZ+RLE hybrid encoder, designed to maximize decoding speed on NMOS 6502 and derived CPUs, while achieving decent compression ratio (for a bytecruncher, that is). It crunches as well as other popular bytecrunchers, while being considerably faster at decrunching."
[...]
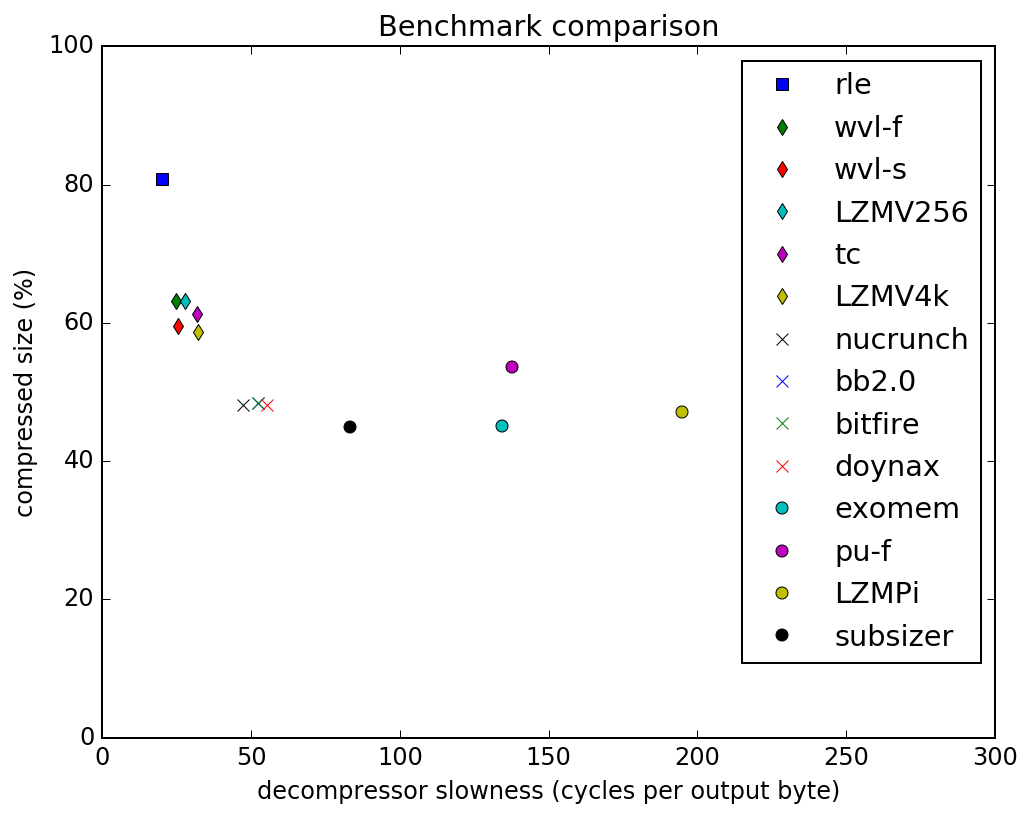
TSCrunch is a bytepacker, with 2byte RLE, 1-2byte LZ tokens and a 512 bytes search window. In this "space" it provides the optimal solution to the puzzle. Exomizer is s different beast, being a bit-cruncher. According to these specs, i'd expect it to fall somewhere into the 60% cluster in the graph below, from https://codebase64.org/doku.php?id=base:compression_benchmarks.
If it is made for in-memory decompression of data, can it also work with prefix data for better compression, i.e., back-referencing to data already in memory (either a static dictionary or, e.g., the previous level)?
And i can't quite follow what "bit-cruncher" vs "byte-cruncher" means. :)
IIRC, Exomizer works on byte-aligned source data as well, also with LZ and RLE.
It produces a bit-stream on the control symbols, though, which is interleaved with byte-aligned literals.
A "bit-cruncher" might maybe be something LZMA- or ANS-like (think ALZ64, or Shrinkler on Amiga), but not Exomizer.
 |
|
... 31 posts hidden. Click here to view all posts....
|
| |
Krill
Registered: Apr 2002
Posts: 2856 |
Quoting Burglarwhen crunchers are this close in compression, throughput is what matters most. Indeed! And in conjunction with loading, there's probably a magic throughput/compression ratio thingy so a block is just barely but still fully decrunched before the next one rolls in, and the ratio good enough so there are not so many more blocks overall than for something hard-core like Exomizer. :) |
| |
Dano
Registered: Jul 2004
Posts: 228 |
Gave it a spin on one of my unreleased anim parts.
For 64 frames of screen and colorram it packs $200 bytes than TinyCrunch. Nice one!
And looking at the mem in C64Debugger it looks noticeably faster.
Great release! |
| |
Krill
Registered: Apr 2002
Posts: 2856 |
Quoting DanoGave it a spin on one of my unreleased anim parts. Sorry for slight off-topic-ness, but... i always wonder if using a non-lossy general-purpose compressor is the right choice for media content. :) |
| |
Dano
Registered: Jul 2004
Posts: 228 |
Depends on what you feed it with and things. Sometimes you want things to be lossless. Sometimes you just want to see where you get with a shovel and hammer. |
| |
ChristopherJam
Registered: Aug 2004
Posts: 1382 |
Great work Tony, it looks like it fits your use case really well.
As you suspected, TinyCrunch has no explicit support for RLE, and performs pretty abysmally on any data with large empty spaces - the maximum match length is 17 bytes, and it uses a two byte token for any matches longer than two bytes, so the compression ratio is capped to 8.5. My own speed demon's on hold for the moment, but as I mentioned on FB, yours will be an interesting one to try and best :) |
| |
Krill
Registered: Apr 2002
Posts: 2856 |
Quoting tonysavonFor my purposes I needed to stay below 20 cycles per output byte, in the general case Could you give a figure for average cycles per input byte? :)
(This is the relevant number to estimate whether a block can be fully decrunched until the next block is received.) |
| |
tonysavon
Registered: Apr 2014
Posts: 24 |
Quote: Quoting tonysavonFor my purposes I needed to stay below 20 cycles per output byte, in the general case Could you give a figure for average cycles per input byte? :)
(This is the relevant number to estimate whether a block can be fully decrunched until the next block is received.)
Sure.
In this metric, if you crunch better you do worse, I guess, because there are fewer bytes to read at the denominator, but this is what I get for Chopper Command amyway:
Total decrunch cycles:
TSCrunch: 799826
TC: 1133039
Dali: 1436401
Crunched file size:
TSCrunch: 13321
TC: 15419
Dali: 10478
Cycles per output byte:
TSCrunch: 17.0
TC: 24.1
Dali: 36.1
Cycles per input byte:
TSCrunch: 60.0
TC: 73.5
Dali: 137.1
|
| |
tonysavon
Registered: Apr 2014
Posts: 24 |
Quote: Great work Tony, it looks like it fits your use case really well.
As you suspected, TinyCrunch has no explicit support for RLE, and performs pretty abysmally on any data with large empty spaces - the maximum match length is 17 bytes, and it uses a two byte token for any matches longer than two bytes, so the compression ratio is capped to 8.5. My own speed demon's on hold for the moment, but as I mentioned on FB, yours will be an interesting one to try and best :)
Well, I'm definitely looking forward to whatever you'll release, especially with that amazing name you chose! :-)
TC is such a nice packer btw, now that I'm looking more and more at it. Lots of clever solutions, and I especially love the two-parts sfx decdunching. Plus all the options it comes with...
Keep up the good working! |
| |
tonysavon
Registered: Apr 2014
Posts: 24 |
All right, I added inplace decrunching, so now it's up to you, @Krill :-)
I'll wait a bit before I bump the version here on CSDb as well, but in the meantime you can download version 1.1 from here:
https://github.com/tonysavon/TSCrunch |
| |
Krill
Registered: Apr 2002
Posts: 2856 |
Quoting tonysavonAll right, I added inplace decrunching, so now it's up to you, @Krill :-) Alright, a few first numbers from the WIP next loader version. =)CPU% ZX0 TS WIN
100 9953 9744 ZX0
90 9086 9437 TS
80 7147 7054 ZX0
70 6222 6328 TS
60 5538 5670 TS
50 4706 4685 ZX0
40 4017 4359 TS
30 3000 3432 TS
20 2030 2404 TS
10 929 1126 TS Bitfire benchmark, numbers are throughput in decrunched bytes per second, higher is better.
Both TSCrunch and ZX0 are quite close to each other, but at just under 50% or less CPU for loading/decrunching, TSCrunch shows its strengths over ZX0.
This matters a lot in a real-world scenario where things are going on while loading in the background. |
| Previous - 1 | 2 | 3 | 4 | 5 - Next |
