| |
Bitbreaker
Registered: Oct 2002
Posts: 508 |
Release id #139503 : Spindle 2.0
So with the spin mode it was now easy to quickly do a speedtest with the files i usually test with (most of the files from cl13 side1).
It turns out that spindle nearly loads as fast as bitfire with on the fly depacking. While bitfire chews in the tracks a tad faster, it has to make breaks to finalize the depacking. So data arrives a bit too fast first and blocks pile up to be decrunched. Spindle manages to have a continuous flow due to its blockwise packing scheme here.
Therefore the 18 files used get squeezed down to 491 blocks, as with bitfire down to 391 blocks. So Spindle leeches an additional 100 blocks in about the time bitfire requires for additional depacking.
However, under load the speed of spindle turns down rapidly, with 25% cpu load it is no faster than krill's loader, with 75% load it takes eons to leech the 491 blocks in :-( What's happening there?!
When is the 50x version from Krill done? :-D HCL, what's the penis length of your loader? :-D
Results here. |
|
... 91 posts hidden. Click here to view all posts....
|
| |
Bitbreaker
Registered: Oct 2002
Posts: 508 |
What else matters? Size (resident that is)? Disk usage? Compatibility? The latter not so much in a demo setting, when it comes to a fast pace and reliable sync points/guaranteed loading times, but of course the best choice for e.g. games. All others matter to some extend. There's never enough RAM, and if the musicians or Bob will steal it. And suddenly you need to rely on speed again to fill all that RAM with another huge binary blob. Best, without ending up with 4 disk side, oops! :-D |
| |
LMan
Registered: Jun 2010
Posts: 83 |
I steal all your RAM with samples. >:-) |
| |
lft
Registered: Jul 2007
Posts: 369 |
Thanks for this work, Bitbreaker!
I will venture a guess as to why Spindle appears to slow down so much at 75% load: As the load goes up, the transfer time goes up, but the time required to fetch disk blocks remains the same. Spindle transfers more data than the other loaders, because of the suboptimal compression, but it normally compensates by fetching the data quicker. In other words, the time spent on fetching blocks dominates for the other loaders, and this time remains constant as load increases. Time spent on transfer dominates for Spindle, and this time increases with the cpu load. |
| |
lft
Registered: Jul 2007
Posts: 369 |
Hmm, I haven't been able to reproduce the rapid decline in speed as cpu load increases.
First I obtained a comparable dataset, consisting of various C64 pictures, music and code. I used 18 files with a total size of 739 blocks. The size on disk is 468 blocks with Spindle, 390 blocks with Bitfire.
Then I measured the number of frames required to load and decrunch the dataset, i.e. using 18 calls to the loader. I get roughly the same speed for both systems, and it seems to scale linearly, so that the transfer rate is halved when the available amount of cpu cycles is halved.
Here you can see the number of frames required:
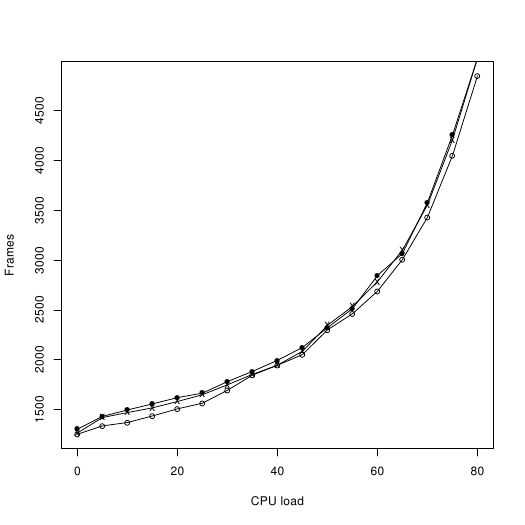
And here I have computed uncompressed_size / frames:
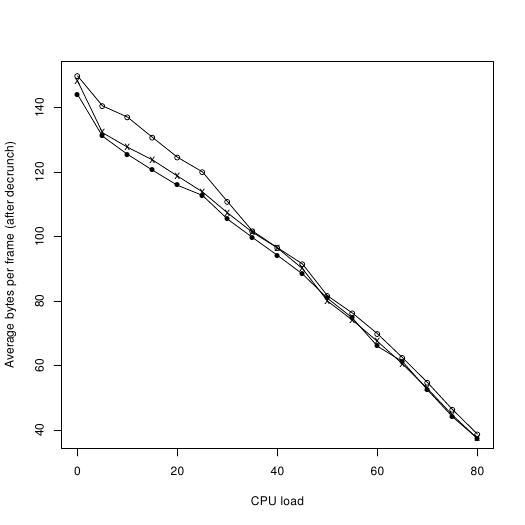
Hollow circle: Spindle.
Cross: Bitfire
Filled circle: Bitfire with motor always on.
Note that the performance of bitfire actually decreases ever so slightly when the motor is left running. I have not been able to figure out how this can happen so consistently.
We can see that Spindle loses its lead at around 25% cpu load. From this point onwards, decrunching is apparently so slow that the drive always has enough time to fetch the next block before it is needed.
Now, there are two things to keep in mind: First, these measurements don't agree with Bitbreaker's, so one of us is probably making a mistake somewhere. Second, Spindle may have a slight speed advantage according to these plots, but it still needs 78 more blocks on disk. I'll have to work on that. |
| |
Bitbreaker
Registered: Oct 2002
Posts: 508 |
Geez, i did a serious mistake: Not removing the sid from the script and playing it %-) this made the 75% case pretty slow :-D
Now when wasting time like in all cases:
none
$ff-$15
$ff-$63
$ff-$b1
Depending on when the cpu is locked (badlines) things can of course vary a bit.
Now spindle starts to outperform bitfire slightly, updated benchmarks: here
Also you can subtract the sid from the 100 blocks overhead, it's something like 56 blocks overhead now. *bummer* |
| |
Oswald
Registered: Apr 2002
Posts: 5094 |
great now add bitfire's packer for win :) |
| |
doynax
Account closed
Registered: Oct 2004
Posts: 212 |
Quoting Oswaldgreat now add bitfire's packer for win :)
That wouldn't work I'm afraid.
Lft's clever scheme is to crunch each and every block independently, allowing them to be fetched out-of-order and decompressed without either the CPU or the drive to ever being stalled while waiting for the "right one" to come around.
The drawback is the lack of context and additional per-block header hurting the compression rate. Plus I imagine grabbing the last few sectors of a track may still be dicey, especially when going full-blast at 100% CPU when you're only doing 5-or-so rounds.
It may be tricky to improve the rates much though. Perhaps by using a block from an old track guaranteed to be available for initial context. Or a RAM-hungry static dictionary scheme of some sort. Or scrounging up the drive RAM for using 512-byte sector pairs as blocks.
Naturally in a perfect world an in-order loader would be the fastest for a completely deterministic demo. Unfortunately slight variations in formatting, drive speed and CPU load makes these quite brittle and susceptible to stalling out for a full revolution on missing a sector, requiring a cautious interleave to compensate.
Incidentally I have had some success in shoring up the performance of an in-order loader by prioritizing fetching over decompression. That is letting the cruncher poll periodically for available sectors from the drive, grabbing them early if available and working from buffered data when stalled. |
| |
Bitbreaker
Registered: Oct 2002
Posts: 508 |
Quoting doynax
Incidentally I have had some success in shoring up the performance of an in-order loader by prioritizing fetching over decompression. That is letting the cruncher poll periodically for available sectors from the drive, grabbing them early if available and working from buffered data when stalled.
That is what krill also introduced with the on the fly depacking by polling for new blocks after each match. I shamelessly copied that jsr call and it helps a lot improving the speed. The depacker usually only stalls in the beginning of files. Maybe it is worth starting in order and then switching to out of order loading after a few blocks piled up.
I also made a full in order loading/depacking version and it ends up being ~25% slower, but therefore allows more or less streaming from disk, with no half filled sectors and such, just one packed file after another being leeched and dropped block by block into memory. |
| |
HCL
Registered: Feb 2003
Posts: 728 |
How come you loose 25% by adding something like..
bit $dd00
bpl *+5
jsr LoadNextSector
+7 cycles for every LZ-bundle.. :) |
| |
Bitbreaker
Registered: Oct 2002
Posts: 508 |
As sectors all arrive in order in the slower case. That is why? |
| Previous - 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 - Next |
