| |
lft
Registered: Jul 2007
Posts: 369 |
Fastloaders & serial transfer timing
This is a continuation of an off-topic discussion in X2016 Competitions: Your Input Wanted!.
There was some concern about serial transfer routines that might fail due to small margins.
I tried adding one safety cycle per bit pair in the transfer routine of Spindle. This caused an average slowdown of 1.5% for my benchmark scenario.
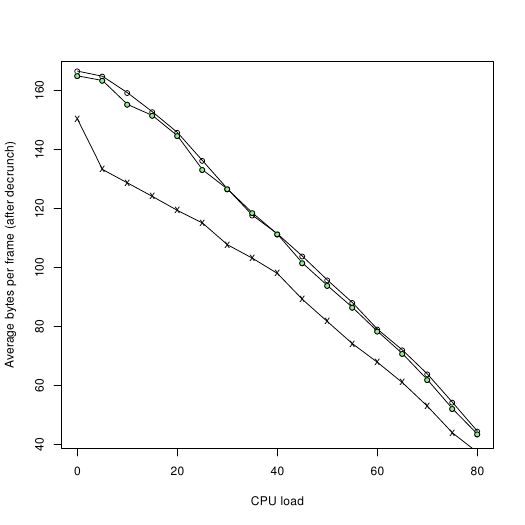
Crosses are bitfire 0.3, just to get some perspective.
Hollow circles are the latest unreleased Spindle with the original (fast) transfer routine.
Green circles are the latest unreleased Spindle with the new (possibly more robust) transfer routine.
I'm thinking that perhaps the robust version should be default, and the fast version available as an option. But on the other hand, nobody has reported any actual issues with the fast code on real drives, so this decision would be based on fear, more or less. Spindle users, what do you say? |
|
... 19 posts hidden. Click here to view all posts....
|
| |
Bitbreaker
Registered: Oct 2002
Posts: 504 |
Quoting sociThese three timings are from Bitfire:
Bitfire 0.5 is just as tight as Spindle. Does it fail on Chameleon in standalone mode too?
Thanks for the test and numbers! So far i have not noticed any drive having problems in the transfer, but due to too strict timing when reading a sector or sector header. This is finally fixed in the next version, even THCM's floppy that is known to be very very picky managed to do a 24h test without any error. I suspect, that this drive is changing clock speed when getting warm in a noticeable way, while rotation speed stays stable. With the three floppys i have at home i never experienced any problems, no matter what i did, so it is about finding those not so in spec drives.
As for chamaeleon i don't know, Groepaz did not rant so far, so guess it is fine :-D |
| |
Bitbreaker
Registered: Oct 2002
Posts: 504 |
Quote: When we had this issue with n0sd0s it seemed to be limited to 1571 drives, just to note.
Means, a drive detection is enough and manipulating the code in case to slow things down, just as one does with NTSC. |
| |
doynax
Account closed
Registered: Oct 2004
Posts: 212 |
Quoting BitbreakerMeans, a drive detection is enough and manipulating the code in case to slow things down, just as one does with NTSC. Alternatively:lda #%00100000
sta $1801
;IRQ transfer loop..
lda #%00000000
sta $1801 |
| |
Bitbreaker
Registered: Oct 2002
Posts: 504 |
In fact 2 MHz mode can be switched on all over, except for the sector reading. Seems to speed up things by ~4% then.
That said, who is going to try it out on his 1571? .d64 is available for testing :-) |
| |
doynax
Account closed
Registered: Oct 2004
Posts: 212 |
Quoting BitbreakerIn fact 2 MHz mode can be switched on all over, except for the sector reading. Seems to speed up things by ~4% then. As long as the track stepping is VIA timed I suppose. Of course in Lft's case sector reading and IEC transmission is basically _all_ there is.
Quoting BitbreakerThat said, who is going to try it out on his 1571? .d64 is available for testing :-) I'll give it a quick whirl for you on my C128D (non-CR) which has survived $1801 pokes in the past. It doesn't suffer from sensitive IEC timing though. |
| |
Flavioweb
Registered: Nov 2011
Posts: 463 |
All this theory could mean that if a real hw drive is connected through another drive (eg running on drive 9 with 8 connected), we can have timing troubles? |
| |
doynax
Account closed
Registered: Oct 2004
Posts: 212 |
Quoting FlaviowebAll this theory could mean that if a real hw drive is connected through another drive (eg running on drive 9 with 8 connected), we can have timing troubles? It will certainly _affect_ the timing. Whether it's a help or a hindrance is difficult to guess at without getting out the oscilloscope. |
| |
chatGPZ
Registered: Dec 2001
Posts: 11357 |
yes, connecting more drives generates more trouble :) some guy reported the weirdest things for chameleon...and then it turned out he had 4 drives connected. doh! |
| |
Bitbreaker
Registered: Oct 2002
Posts: 504 |
A lot of tests and pain was gained on tests on real hardware and it turned out that serial is not the biggest problem to cope with. A loader should also sustain some variation in rotation speed. Also in very rare cases it is not enough to rely on the checksum, neither of the header nor the payload. When spinning up and starting directly to load, it can happen that one still passes all tests and load chunk. Been there, seen that. Same goes if you ommit a check on right track during header sanity checks. It might happen that for a short while you are reading from a neighbour track after stepping, with valid checksums of course. All problems that do not occur on emulated hardware but might let you fail after a bunch of successful runs over a whole disk.
Another though: if you populate the gaps in specific gcr_decode tables with other variables/data to make optimum use of your floppy ram, there is another potential risk:
When reading chunk while spinning up/stepping one could also read invalid gcr codes and make looukups in the gaps. If we have zeroes there, it is an easier to get a false positive checksum. As we read an arbitrary amount of zeroes, we will match with a zero checksum as well, though we have just read nothing. But i have no yet checked, thought of what the floppy is reading if there's no change in polarization, maybe 00000 all over? |
| |
doynax
Account closed
Registered: Oct 2004
Posts: 212 |
Quoting BitbreakerA lot of tests and pain was gained on tests on real hardware and it turned out that serial is not the biggest problem to cope with. A loader should also sustain some variation in rotation speed. Also in very rare cases it is not enough to rely on the checksum, neither of the header nor the payload, ... It seems to me that what is really called for is a stronger checksum. More carefully tuned drivecode is going to keep failing regardless, during disk swaps and mechanical problems if nothing else.
I don't know quite what though. A one's complement sum would be a start though, with the sector header and data block sums linked in.
I suppose anything fancier is tricky on a single-accumulator machine though but fletcher-16 is doable, and CRC-8 is only 6 extra cycles per byte if you can afford the 256-byte table. Probably an 8-bit sum in parallel with the standard parity byte would be quite sufficient though.
As has been noted a clearer error model to work with would certainly also help in evaluating the candidates.
Side-note: Things get rather interesting when combined with Kabuto's arithmetic coding, which sort-of makes errors cascade by default. Combined with a header swizzled into the middle of the payload I figure an 8-bit one's complement sum is farily decent. Of course having been to lazy to bothered doing the analysis and it is quite possible that the two arithmetic codes interact badly ;) |
| Previous - 1 | 2 | 3 - Next |
