| |
Bitbreaker
Registered: Oct 2002
Posts: 508 |
Release id #139503 : Spindle 2.0
So with the spin mode it was now easy to quickly do a speedtest with the files i usually test with (most of the files from cl13 side1).
It turns out that spindle nearly loads as fast as bitfire with on the fly depacking. While bitfire chews in the tracks a tad faster, it has to make breaks to finalize the depacking. So data arrives a bit too fast first and blocks pile up to be decrunched. Spindle manages to have a continuous flow due to its blockwise packing scheme here.
Therefore the 18 files used get squeezed down to 491 blocks, as with bitfire down to 391 blocks. So Spindle leeches an additional 100 blocks in about the time bitfire requires for additional depacking.
However, under load the speed of spindle turns down rapidly, with 25% cpu load it is no faster than krill's loader, with 75% load it takes eons to leech the 491 blocks in :-( What's happening there?!
When is the 50x version from Krill done? :-D HCL, what's the penis length of your loader? :-D
Results here. |
|
| |
Krill
Registered: Apr 2002
Posts: 2980 |
That 50x screen-off fastloader cannot be compared to these IRQ loaders now, can it? :)
And as you see, even the IRQ loaders are difficult to compare already in the seemingly simplest department, speed.
But for futher tests, please do add version numbers on all the loaders, as these speed figures will change. (Yes, i still intend to add those speed improvements which have been on my list for years.) :) |
| |
Bitbreaker
Registered: Oct 2002
Posts: 508 |
What else matters? Size (resident that is)? Disk usage? Compatibility? The latter not so much in a demo setting, when it comes to a fast pace and reliable sync points/guaranteed loading times, but of course the best choice for e.g. games. All others matter to some extend. There's never enough RAM, and if the musicians or Bob will steal it. And suddenly you need to rely on speed again to fill all that RAM with another huge binary blob. Best, without ending up with 4 disk side, oops! :-D |
| |
LMan
Registered: Jun 2010
Posts: 83 |
I steal all your RAM with samples. >:-) |
| |
lft
Registered: Jul 2007
Posts: 369 |
Thanks for this work, Bitbreaker!
I will venture a guess as to why Spindle appears to slow down so much at 75% load: As the load goes up, the transfer time goes up, but the time required to fetch disk blocks remains the same. Spindle transfers more data than the other loaders, because of the suboptimal compression, but it normally compensates by fetching the data quicker. In other words, the time spent on fetching blocks dominates for the other loaders, and this time remains constant as load increases. Time spent on transfer dominates for Spindle, and this time increases with the cpu load. |
| |
lft
Registered: Jul 2007
Posts: 369 |
Hmm, I haven't been able to reproduce the rapid decline in speed as cpu load increases.
First I obtained a comparable dataset, consisting of various C64 pictures, music and code. I used 18 files with a total size of 739 blocks. The size on disk is 468 blocks with Spindle, 390 blocks with Bitfire.
Then I measured the number of frames required to load and decrunch the dataset, i.e. using 18 calls to the loader. I get roughly the same speed for both systems, and it seems to scale linearly, so that the transfer rate is halved when the available amount of cpu cycles is halved.
Here you can see the number of frames required:
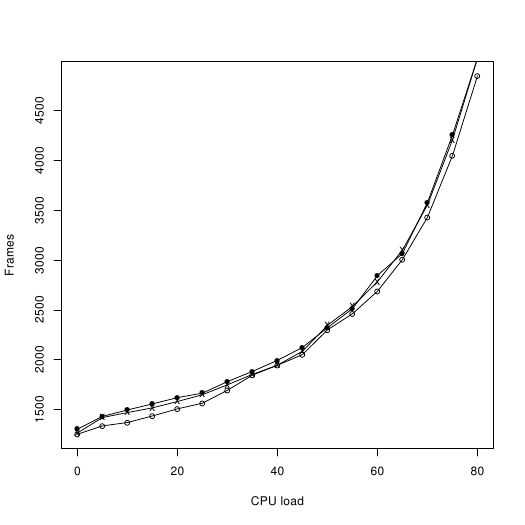
And here I have computed uncompressed_size / frames:
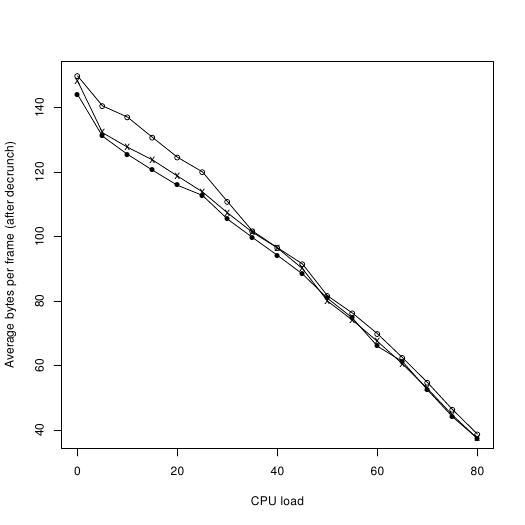
Hollow circle: Spindle.
Cross: Bitfire
Filled circle: Bitfire with motor always on.
Note that the performance of bitfire actually decreases ever so slightly when the motor is left running. I have not been able to figure out how this can happen so consistently.
We can see that Spindle loses its lead at around 25% cpu load. From this point onwards, decrunching is apparently so slow that the drive always has enough time to fetch the next block before it is needed.
Now, there are two things to keep in mind: First, these measurements don't agree with Bitbreaker's, so one of us is probably making a mistake somewhere. Second, Spindle may have a slight speed advantage according to these plots, but it still needs 78 more blocks on disk. I'll have to work on that. |
| |
Bitbreaker
Registered: Oct 2002
Posts: 508 |
Geez, i did a serious mistake: Not removing the sid from the script and playing it %-) this made the 75% case pretty slow :-D
Now when wasting time like in all cases:
none
$ff-$15
$ff-$63
$ff-$b1
Depending on when the cpu is locked (badlines) things can of course vary a bit.
Now spindle starts to outperform bitfire slightly, updated benchmarks: here
Also you can subtract the sid from the 100 blocks overhead, it's something like 56 blocks overhead now. *bummer* |
| |
Oswald
Registered: Apr 2002
Posts: 5094 |
great now add bitfire's packer for win :) |
| |
doynax
Account closed
Registered: Oct 2004
Posts: 212 |
Quoting Oswaldgreat now add bitfire's packer for win :)
That wouldn't work I'm afraid.
Lft's clever scheme is to crunch each and every block independently, allowing them to be fetched out-of-order and decompressed without either the CPU or the drive to ever being stalled while waiting for the "right one" to come around.
The drawback is the lack of context and additional per-block header hurting the compression rate. Plus I imagine grabbing the last few sectors of a track may still be dicey, especially when going full-blast at 100% CPU when you're only doing 5-or-so rounds.
It may be tricky to improve the rates much though. Perhaps by using a block from an old track guaranteed to be available for initial context. Or a RAM-hungry static dictionary scheme of some sort. Or scrounging up the drive RAM for using 512-byte sector pairs as blocks.
Naturally in a perfect world an in-order loader would be the fastest for a completely deterministic demo. Unfortunately slight variations in formatting, drive speed and CPU load makes these quite brittle and susceptible to stalling out for a full revolution on missing a sector, requiring a cautious interleave to compensate.
Incidentally I have had some success in shoring up the performance of an in-order loader by prioritizing fetching over decompression. That is letting the cruncher poll periodically for available sectors from the drive, grabbing them early if available and working from buffered data when stalled. |
| |
Bitbreaker
Registered: Oct 2002
Posts: 508 |
Quoting doynax
Incidentally I have had some success in shoring up the performance of an in-order loader by prioritizing fetching over decompression. That is letting the cruncher poll periodically for available sectors from the drive, grabbing them early if available and working from buffered data when stalled.
That is what krill also introduced with the on the fly depacking by polling for new blocks after each match. I shamelessly copied that jsr call and it helps a lot improving the speed. The depacker usually only stalls in the beginning of files. Maybe it is worth starting in order and then switching to out of order loading after a few blocks piled up.
I also made a full in order loading/depacking version and it ends up being ~25% slower, but therefore allows more or less streaming from disk, with no half filled sectors and such, just one packed file after another being leeched and dropped block by block into memory. |
| |
HCL
Registered: Feb 2003
Posts: 728 |
How come you loose 25% by adding something like..
bit $dd00
bpl *+5
jsr LoadNextSector
+7 cycles for every LZ-bundle.. :) |
| |
Bitbreaker
Registered: Oct 2002
Posts: 508 |
As sectors all arrive in order in the slower case. That is why? |
| |
Krill
Registered: Apr 2002
Posts: 2980 |
Quoting BitbreakerWhat else matters? Size (resident that is)? Disk usage? Compatibility? Of course, speed is the most important measure in the end for top-rated demos. But yes, compatibility and arcane things like "ease of use" do matter as well, in other contexts.
Furthermore, every top-notch group will end up rolling their own loader sooner or later, if only for "not invented here" reasons to dismiss other solutions. Everybody else chooses some existing loader, and then decides which one to use on many factors. Speed not being that important any more because there is less requirement for it compared to the latest iteration of colour cyclers/sample replay/blocky video. :)
That said, you still haven't added version numbers in your stats.
Oh, and i don't quite trust those numbers. I've been getting around 3.5-4 kB/s raw transfer speed for years (of course under optimal conditions, which i'm sure you also keep a close eye on for the number dearest to you), and yet i see significantly lower numbers in your graphs.
I also think the numbers should be separated for the four track zones, with some (weighted) average to boil them down to one number in the end. |
| |
Bitbreaker
Registered: Oct 2002
Posts: 508 |
Quoting KrillOf course, speed is the most important measure in the end for top-rated demos. But yes, compatibility and arcane things like "ease of use" do matter as well, in other contexts.
Furthermore, every top-notch group will end up rolling their own loader sooner or later, if only for "not invented here" reasons to dismiss other solutions. Everybody else chooses some existing loader, and then decides which one to use on many factors. Speed not being that important any more because there is less requirement for it compared to the latest iteration of colour cyclers/sample replay/blocky video. :)
That said, you still haven't added version numbers in your stats.
Oh, and i don't quite trust those numbers. I've been getting around 3.5-4 kB/s raw transfer speed for years (of course under optimal conditions, which i'm sure you also keep a close eye on for the number dearest to you), and yet i see significantly lower numbers in your graphs.
I also think the numbers should be separated for the four track zones, with some (weighted) average to boil them down to one number in the end.
Feel free to do so! |
| |
lft
Registered: Jul 2007
Posts: 369 |
Krill, your loader is an exemplary piece of engineering. It is highly configurable and supports a multitude of use cases where regular files or IFFL are desirable. Bitfire and Spindle specifically address the modern fast-paced trackmo. I think everybody knows this, that we are trading genericity for speed, but it doesn't hurt to state it explicitly.
Quoting Krillyou still haven't added version numbers in your stats.
For my graphs, that would be Spindle 2.0 and Bitfire 0.3.
Quote:I also think the numbers should be separated for the four track zones, with some (weighted) average to boil them down to one number in the end.
This is a good idea. |
| |
Oswald
Registered: Apr 2002
Posts: 5094 |
let's not forget that bitfire is a mod of krill's loader, which is the most used loader ever and was amongst the fastest (if not the) until a year ago or so. |
| |
Bitbreaker
Registered: Oct 2002
Posts: 508 |
Quote: let's not forget that bitfire is a mod of krill's loader, which is the most used loader ever and was amongst the fastest (if not the) until a year ago or so.
A mod? Krills loader was a very good example of a working loader, that is why i used it to learn how a loader works in detail. Of course i also lend ideas and codesnippets, but also from other loaders like polish loaders and also from the first spindle version. There's no need to reinvent the wheel for things that are common knowledge. I wanted to get the concept of a predictable sectorchain (with 256 bytes payload that is) to run and see how it would perform. Also i wanted to have a way smaller resident loader part. Nevertheless, i wrote the whole thing from scratch and evolved from there and shrunk code from there and also replaced a lot of stuff with own routines, as they allow for more tolerance, or are smaller or faster.
So have you ever looked into the code and have compared? The only similiar things might be the checksumming and slight parts of the gcr decoding, transfer. Really, this bitching starts to piss me off.
Also, it is not my fault if krill has no time to improve his loader, i preferred to do my own then before waiting for years. There's no need to doubt in the need, stuff like the huge gfx scroller in comaland would not be possible with a slower loader/depacker combination, as the next pic would not arrive in time (it is going in 50fps, not the usual 25).
Also, here's an updated benchmark for krill's loader (#146 that is) disk written with an interleave of 5 and loadraw as example. $5e9 (see @ $0959 after loading finishes) frames is what i get so not much difference but slightly better. Feel free to give me hints on how to make this benchmark even faster, and then stop all that bitching and whining about a hurt butt already and work on faster loaders, smaller loaders, your next demo, so that there is no need anymore to complain about just a few groups dominating at the moment.
penis.d64
</rant> |
| |
Oswald
Registered: Apr 2002
Posts: 5094 |
"i wrote the whole thing from scratch .. and also replaced a lot of stuff with own routines"
o really? :)
"Submitted by Krill [PM] on 27 October 2014
Dr.j: As far as i understood it, Bitbreaker took my loader, removed everything not strictly needed by a demo "
also looking at someone else's source code and taking over ideas hardly qualifies as "taking over some common knowledge" in my book. sounds like everyone and his dog could write a loader. Without krill's source you wouldnt be able to make bitfire or it would have taken 10x as much work. So give credit where its due. |
| |
chatGPZ
Registered: Dec 2001
Posts: 11386 |
lol |
| |
Bitbreaker
Registered: Oct 2002
Posts: 508 |
Sorry, i did line vectors, filled vectors and all other kind of stuff recently. I guess i also forgot to give proper credit there, as i am sure others did those effects before me and i might have done things in a similiar manner. I guess i shamelessly copied everything there too and just removed the unnecessary stuff to make it faster. m(
Have you compared the fucking source meanwhile or do you prefer talking more bullshit?
The real mod is in bitnax, where i picked up doynax source and adopted it to my needs. |
| |
Oswald
Registered: Apr 2002
Posts: 5094 |
its not that you're not the uncrowned kign of line routines, also i understand you did a LOT of work on bitfire, and giving away from free is a great move aswell. but from gunnar's and your reaction it feels you took most of his loader. thats not a problem. but sentences like "I rewrote it from scratch and even replaced some routines with my own" makes me raise my eyebrow. |
| |
chatGPZ
Registered: Dec 2001
Posts: 11386 |
try looking at the source? |
| |
Oswald
Registered: Apr 2002
Posts: 5094 |
dont have hours to waste. anywas sorry for stirring this shit up. peace all. bitfire looks really cool, hope to try it out soon. |
| |
chatGPZ
Registered: Dec 2001
Posts: 11386 |
lol |
| |
Krill
Registered: Apr 2002
Posts: 2980 |
Quoting BitbreakerFeel free to give me hints on how to make this benchmark even faster, and then stop all that bitching and whining about a hurt butt already and work on faster loaders, smaller loaders, your next demo, so that there is no need anymore to complain about just a few groups dominating at the moment. Was that directed at Oswald or me? Anyhow, will take a close look at it soon. And there's no butthurt here, as far as i can tell, and you're right about simply making new stuff rather than complaining. I was merely remarking about a perceived mis-representation.
Referring to credits and all, in Bitfire V0.1 there's a credit for me, and i'm fine with that. That case was closed a while ago. :) |
| |
Krill
Registered: Apr 2002
Posts: 2980 |
Quoting lftBitfire and Spindle specifically address the modern fast-paced trackmo. I think everybody knows this, that we are trading genericity for speed, but it doesn't hurt to state it explicitly. True. And i do not expect to surpass them in speed anytime soon (unless i come up with some new ideas), but be slightly slower, thanks to the "genericity overhead." :) |
| |
Bitbreaker
Registered: Oct 2002
Posts: 508 |
Quote: its not that you're not the uncrowned kign of line routines, also i understand you did a LOT of work on bitfire, and giving away from free is a great move aswell. but from gunnar's and your reaction it feels you took most of his loader. thats not a problem. but sentences like "I rewrote it from scratch and even replaced some routines with my own" makes me raise my eyebrow.
I would have loved to have lft's on the fly gcr decoding implemented, but it turned out to take up too much mem in the floppy, so i first used the partial gcr method from the krill loader, in the following versions i then exchanged that part with new code that allows for more timing tolerance and decodes a bit more gcr bits in the inner loop. Protocol is standard 2 bit atn, so nothing new here for most loaders. The main thing is, that pretty much things work very different to krill's loader, as i do not work by track/sector chains (just like lft as well), so i have 256 payload per sector what takes away a lot of complexity and pain, but brings other problems like the need of an own directory format, and thus also an own d64-image writer (We don't want to seek track 18 anyway all the time). Also the turn disk detection was easy to implement that way, avoiding the usual pitfalls with wrong disk-ids or flaky photo sensor code. The other stuff that i did similiar was the serialization of blocks on c64 side, in the yet unreleased version this is all offloaded to the floppy, as it is easier to set barriers there, the wanted sector list exists there and one can work on that, no need for an extra blockmap. From spindle 1 i used the stepping method, it looked slim but even that i managed to shrink. But the the stepping code is not much rocket science, i guess the hardest point is to get the gcr header and sector decoding done as fast as possible and without hanging on real hardware. It is not slapped together quickly, but developed over quite some time now. Take into account that i can invest pretty much time into demoscenestuff, and always have THCM at hand to test current images on real hw.
I hope this makes further clear that it is not just a mod, what i define as changes on already existing source. My favourite assembler is acme, it is the workflow i am used to and it is easier to do things from scratch, than modifying existing code anyway. All that said, if you ever happen to examine the code of bitfire (but also a look into krill's and the spindle code is worth it) you will notice that there's not much in common between krill's loader and the others, except the register sets of the VIAs and the gcr decoding scheme and sector read timings that one always has to cope with. |
| |
Bitbreaker
Registered: Oct 2002
Posts: 508 |
Quote: Quoting lftBitfire and Spindle specifically address the modern fast-paced trackmo. I think everybody knows this, that we are trading genericity for speed, but it doesn't hurt to state it explicitly. True. And i do not expect to surpass them in speed anytime soon (unless i come up with some new ideas), but be slightly slower, thanks to the "genericity overhead." :)
An as fast gcr decoding as done by lft but with your memory footprint would be the thing that would give the gain. I pondered a lot about it but so far the methods that manage that in one pass use pretty much mem for that (the loader used by BD as well, and it is most likely slower than krill's loader though, OOO wins as it seems).
As for the benchmark, let me know if i do anything wrong with the usage of your loader. For me that is the maximum that i can squeeze out on that penis.d64.
And yes, i share all the source and i am happy that all others do too. No need to read up things in binaries anymore. And i am happy if others get inspired by my or others achievements and try it even better. That is pretty much what all the demoscene is about, and it is the source of all the motivation put into it. |
| |
Krill
Registered: Apr 2002
Posts: 2980 |
Quoting BitbreakerI pondered a lot about it but so far the methods that manage that in one pass use pretty much mem for that (the loader used by BD as well, and it is most likely slower than krill's loader though, OOO wins as it seems). Interesting, but both techniques are not mutually exclusive, are they? Which brings me back on topic: in Spindle, GCR decoding is done on-the-fly, in one pass, alright - but checksumming still is done in a second pass, and while receiving the data on the C-64 side? |
| |
Bitbreaker
Registered: Oct 2002
Posts: 508 |
Quote: Quoting BitbreakerI pondered a lot about it but so far the methods that manage that in one pass use pretty much mem for that (the loader used by BD as well, and it is most likely slower than krill's loader though, OOO wins as it seems). Interesting, but both techniques are not mutually exclusive, are they? Which brings me back on topic: in Spindle, GCR decoding is done on-the-fly, in one pass, alright - but checksumming still is done in a second pass, and while receiving the data on the C-64 side?
Seems so, and what is a good thing, as it secures also the data transmission, if an error occurs there, the chcksum most likely also fails. Defenitely a win! the checksumming happens during transmission and the blocks get either acked or nacked on bad checksum. I calculated the gain/overhead if checksumming oon c64 side, as for my case it doesn't bring any gain but also no loss (speedwise that is) |
| |
HCL
Registered: Feb 2003
Posts: 728 |
Common guys, give this guy some credit. He has obviously done a great job in drive code development.. Hmm, i'm talking about BitBreaker now, but the same goes for Lft of course :D.
Even if he looks at other's code, and even uses it, i have to admit at this point that i do that as well! Looking at other's code is probably what inspires me the most, sometimes it gives me an idea of how to do it better, and perhaps i do it. It's only every now and then that i come across something original, like rotating rasterbars or such.. that i can really take the full credit for myself.
Then i guess we do have a problem with how this guy expresses himself, i do at least.. He is yelling a bit more than some others, he uses genital words alot, and he seems to like being in the spotlight. FUCK HIM for that :E, ok so now we can just calm down and try to see what he is creating instead. Annoying also that he seems to have alot more time to spend on this thing, that we all could easily spend a 50% occupation on :).
Now what was this thread about again!? Spindel 2.0?? Never heard of it ;) |
| |
Danzig
Registered: Jun 2002
Posts: 440 |
Finalizing this thread:
* you are all dumbfucks, 'coz you use software for development coded by others (Turboassembler, Acme, Kickassembler, ..). please go back and use basic with read and data for generating your assembler code :) only using basic is valid because it's build-in!
* you are all dumbfucks, 'coz you peek in other peoples code. this is not the right thing to do! exception: there is a license like lgpl granting permission. Otherwise you are one foot in jail. Really!
* you are all dumbfucks, 'coz you run up the hill instead of keeping calm. Oswald trolls and you all step in the trap.
* you are all dumbfucks, 'coz Bitbreaker compares penis and you all step in the trap.
* you are all dumbfucks, 'coz every researcher starts from ground zero. Always! Ever! I promise!
You see, it's not pretty easy in 2015 to get the reputation you want when working with aces like Axis, Bob and THCM :)
Tobi, you've gone places! You deserve where you are.
You see, it's not pretty easy in 2015 to accept the reputation you got when your loader is aging. :)
Gunnar, you're still there! Your work is awesome and we love you.
You see, it's not pretty easy in 2015 to keep trolling high level when the last meme containing your name is unposted for years. :)
Oswald, you're a still strong within the trolling force. You should better code some new demo but still...
You see, it's not pretty easy in 2015 to stop commenting with 'lol' and 'rofl' even if you quit being mod. :)
Groepaz, you're still the most annoying but beloved scener there is. You have a place in our heart.
You see, it's not easy in 2015 to stop being amoused about all the rant and bitch fighting when your demo is still the best ever since X-2008. :)
HCL, you're you. And that is good. You will top yourself one day :D |
| |
chatGPZ
Registered: Dec 2001
Posts: 11386 |
pfff, as if me being an annoying twat has anything to do with being mod on csdb =) |
| |
ChristopherJam
Registered: Aug 2004
Posts: 1409 |
Thread delivers. Now where's my "like" button. |
| |
ChristopherJam
Registered: Aug 2004
Posts: 1409 |
(also, I really must get back to loader/cruncher coding. Just as soon as I've finished tidying up three or four other c64 projects...) |
| |
mankeli
Registered: Oct 2010
Posts: 146 |
:3
 |
| |
HCL
Registered: Feb 2003
Posts: 728 |
Oh, guys.. You just had a great opportunity to leave Danzig's rant remain unposted.. FOR YEARS!! :D. You bummers :P.. |
| |
Bitbreaker
Registered: Oct 2002
Posts: 508 |
Updated results here
Now also added features and corrected numbers for Krill with interleave 5, as well as for bitfire. Also BD-loader got added and an overview on the feature sets. Let me know if i missed or broke something. |
| |
Danzig
Registered: Jun 2002
Posts: 440 |
Quote: Oh, guys.. You just had a great opportunity to leave Danzig's rant remain unposted.. FOR YEARS!! :D. You bummers :P..
your are all dumbfucks, 'coz I "finalized" the thread to keep it alive and you all step into the trap ;)
/me wants coop between lft and bitbreaker: spitfire :D |
| |
MagerValp
Registered: Dec 2001
Posts: 1078 |
And ULoad M3 is slower than all of the above, uses more RAM, and can't handle sprites being enabled. Plus I stole all the code from Lasse Öörni. *Now* who's the lamer here? |
| |
ChristopherJam
Registered: Aug 2004
Posts: 1409 |
Thanks for doing those benchmarks, Bitbreaker.
Here's an alternate view of the results, if I'm interpreting the data correctly.
How many bytes can we snaffle per raster line, and how many cpu-cycles does it take to acquire each byte?
Perhaps relevant if you're trying to work out how much you can stream if you allow 30 or 40 rasterlines of border time..

 |
| |
Burglar
Registered: Dec 2004
Posts: 1101 |
nice thread this, especially with a bit of mudslinging ;)
how many blocks/sectors are used with each loader? I guess bitbreaker didnt care about size (he'll just add another disk;), but I do :)
also, how come bd-loader beats krill, even though it doesnt support out-of-order loading? what magic spells did you cast, hcl? |
| |
Oswald
Registered: Apr 2002
Posts: 5094 |
fixed order loading is the key for all those loaders beating krill's one. you dont need extra time to wait for sectors or find out their order beforehand. |
| |
Burglar
Registered: Dec 2004
Posts: 1101 |
Quoting Oswaldfixed order loading is the key for all those loaders beating krill's one. you dont need extra time to wait for sectors or find out their order beforehand.
no, yes, you just described out of order loading, and yes thats why spindle+bitfire are on top, and they beat krill cause they don't need to scan the track first to figure out whats what. but my question remains, why does HCL beat Krill? bd-loader does not load out of order, it must miss a sector every once in a while, so whats the deal? ;) |
| |
Bitbreaker
Registered: Oct 2002
Posts: 508 |
Burglar, mind the note i added for BD-loader, i chose teh best interleave per load, in real of course you need to decide for one interleave and then certain loads will suck in performance. The old tradeoff. HCL also gave me a version where the motor is on and it nearly reaches spindle/bitfire speeds, when cheating the benchmarks like that :-D So with the OOO-loaders performance will decrease linearly, with in order exorbitant. |
| |
HCL
Registered: Feb 2003
Posts: 728 |
I don't know why setting up the sector orden manually is cheating, it must be some pro-ooo-loading propaganda. Also i will not get bad performance if cpu-load varies since i can change the interleave for each file. Of course ooo solves that problem nicely, but not always faster.
Some words about the motor on/off thing. It became clear to me after seing my loader/decruncher in Bitbreaker's benchmark that i'm loosing helluvalot in the beginning of each file since the motor is turned off rapidly after each load. I just made a small patch and let it run instead just like all other loaders in the benchmark (i suppose), and voila that gave me ~25% lower loading times. That is of course since this benchmark has quite many small files, but please am i cheating the benchmark!?!?! I just wonder why you put my slowest numbers in that chart, is it because the better numbers voidifies the belief of ooo? You don't gain any 30% or such, it's merely at around 5% or what?! The saga continues :).. |
| |
Ksubi
Account closed
Registered: Nov 2007
Posts: 87 |
Out of curiosity... how does Mr Wegi's loader compare to these?
Bongo Linking Engine |
| |
Bitbreaker
Registered: Oct 2002
Posts: 508 |
Quote: I don't know why setting up the sector orden manually is cheating, it must be some pro-ooo-loading propaganda. Also i will not get bad performance if cpu-load varies since i can change the interleave for each file. Of course ooo solves that problem nicely, but not always faster.
Some words about the motor on/off thing. It became clear to me after seing my loader/decruncher in Bitbreaker's benchmark that i'm loosing helluvalot in the beginning of each file since the motor is turned off rapidly after each load. I just made a small patch and let it run instead just like all other loaders in the benchmark (i suppose), and voila that gave me ~25% lower loading times. That is of course since this benchmark has quite many small files, but please am i cheating the benchmark!?!?! I just wonder why you put my slowest numbers in that chart, is it because the better numbers voidifies the belief of ooo? You don't gain any 30% or such, it's merely at around 5% or what?! The saga continues :)..
You drama queen! :-D Turning the motor off so fast gives of course a penalty in your case and leaving it on is valid, but the different interleaves are kind of cheating. Of course you can write each file with a different interleave, but you won't be able to place 2 files with different interleave on a same track. All unnecessary pain in the ass that is easily covered with OOO. Even i had to learn that, by first loading in order on my first prototypes. Now i just compile a demo and know that speeds will always behave well, no fiddling with interleaves, more time to draw boobs and do bitching :-D I'll update the numbers with motor soonish, need to try some new stolen code first on my loader :-) |
| |
JackAsser
Registered: Jun 2002
Posts: 2014 |
Just a thought that's emerging in my mind, a thought I'll never implement hence I just share it without and see where it leads: Wouldn't it be possible to devise a compression method that guarantees no two consecutive zero-bits in a row, thus remove the need for GCR-encoding completely. I.e. each nibble read from the disk has a direct meaning to the decompressor? |
| |
ChristopherJam
Registered: Aug 2004
Posts: 1409 |
Quote: Just a thought that's emerging in my mind, a thought I'll never implement hence I just share it without and see where it leads: Wouldn't it be possible to devise a compression method that guarantees no two consecutive zero-bits in a row, thus remove the need for GCR-encoding completely. I.e. each nibble read from the disk has a direct meaning to the decompressor?
Absolutely! However, as there would be less information per bit, you would then need to transfer more bits from the drive. Whether that would be a win or not probably depends on CPU load; if you're just trickling a little data per frame then the disk reads and GCR decode are effectively free, so you'd likely gain nothing. However, if you're screen blanked and hammering the sector reads, it might actually help :) |
| |
HCL
Registered: Feb 2003
Posts: 728 |
I understand that you are proud of your loader Bitboy, i would be as well. But when it comes to speed, it seems like old-school demo-shit works about just as good as your modern stuff.
Then i admit it must be a bugger for you to run my shit in the benckmark since you have to transfer 4 disks with different interleave if you want to run it on real HW :P, i'm sorry for that, but is it cheating? Normally you re-generate your .d64 all the time anyway. It's not that you generate it just once and then start thinking of how to load it (or avoid thinking of it in your case).. Now i have to think one minute on how the files are placed on the disk if i want maximum performance (which i rarely do btw, but that's another story :P). Btw, you are already cheating then because you're using a special d64-tool that places your files in track-order(!).
Quote:need to try some new stolen code first on my loader :-) (!) :O /o\.. and you call *me* a drama queen ;). |
| |
doynax
Account closed
Registered: Oct 2004
Posts: 212 |
Isn't it about time to settle on a standard loader test corpus?
Expecting a single developer to accurately compare his or her own carefully-tuned work to semi-documented off-the-shelf libraries seems dubious, whether in the C64 scene or in academia.
Admittedly no data set is ever going to be perfectly representable and certainly reliability, whether in the form of hardware compatibility or insensitivity to variance, would be penalized by a pure speed metric. It would still serve as an interesting challenge though.
The condition may also be modified slightly, say by introducing a random CPU load and a range of rotational speeds to accommodate.
Quoting JackAsserWouldn't it be possible to devise a compression method that guarantees no two consecutive zero-bits in a row, thus remove the need for GCR-encoding completely. I.e. each nibble read from the disk has a direct meaning to the decompressor? Possibly. You could certainly device a Huffman-esque binary prefix code avoiding unrepresentable sequences but it may be difficult to rival the performance of traditional LZ with literal bytes, especially in terms of RAM for tables/buffers. The real kicker is that you'd be shifting load from the drive to the main CPU, both due to additional decode work and transfer overhead.
Plus the 10x one-bit limit is surprisingly annoying.
Quoting BitbreakerOf course you can write each file with a different interleave, but you won't be able to place 2 files with different interleave on a same track. I don't see why not. Admittedly loaders without CBM linking or custom formatting would require per-track interleave tables.
The results of mixed strides will naturally be worse but a decent optimizer can still do a reasonable job of it. After all things never did line up perfectly even with a fixed interleave.
The ideal in-order loader would use a profiling pass with a dummy loader (e.g. a cartridge build) to measure the elapsed time between sector transfers. Data which would then be fed back to the layout optimizer. Perhaps refined with a programmable safety margin and priorities or deadline measurements to weigh non-critical files. |
| |
Krill
Registered: Apr 2002
Posts: 2980 |
Quoting ChristopherJamHow many bytes can we snaffle per raster line, and how many cpu-cycles does it take to acquire each byte? If you mean raw transfer power from drive to C-64, my rule of thumb is about 2 bytes per scanline. That is 28 cycles for the actual byte (the usual lda $dd00:lsr:lsr:ora $dd00:... business), times 2, plus a bit of overhead for storing and re-syncing once in a while. |
| |
Krill
Registered: Apr 2002
Posts: 2980 |
Quoting Oswaldfixed order loading is the key for all those loaders beating krill's one. you dont need extra time to wait for sectors or find out their order beforehand. It's not about fixed-order loading vs. out-of-order loading, it's about the last point you mentioned: knowing the sector layout beforehand. When there is no need to scan a track before actually loading anything, you can still load whatever file block happens to pass by and put its data at the right place in C-64 memory.
And yes, this is the main reason for the discussed speed differences. While today's loaders require about 4 to 5 revolutions to read an entire track, an extra scan revolution gives quite a bit of penalty compared to a carefully hand-crafted sector layout. |
| |
Krill
Registered: Apr 2002
Posts: 2980 |
Quoting doynaxThe ideal in-order loader would use a profiling pass with a dummy loader (e.g. a cartridge build) to measure the elapsed time between sector transfers. Data which would then be fed back to the layout optimizer. Perhaps refined with a programmable safety margin and priorities or deadline measurements to weigh non-critical files. And it probably requires a mastering process that would align the sectors. When transferring disk images with the usual tools these days, you end up with more or less random track-to-track offsets of the sectors. But you want the first block passing by on the next track to be the next one in your data stream. |
| |
Bitbreaker
Registered: Oct 2002
Posts: 508 |
Quoting HCLBtw, you are already cheating then because you're using a special d64-tool that places your files in track-order(!).
Try harder :-) I write out everything in interleave 4, no matter what, but i throw away that annoying t/s links. Spindle does about the same, and both have the best speed possible with it, out of the box, no further tweaking and tuning necessary. If you mean that i write files in a sequential order, everyone would do so, also your disk tool ;-) It's 2015. Why not going for more sophisticated stuff? Cross development entered demomaking, cross-packing did, emulators did, Makefiles did. Further more you could simply OOO enable your loader, there's enough mem free for that, and the few bytes you need on c64 side for it are easily saved. just as you were able to squeeze all in below the magic $200. No need to name the shortcomings of a technique a feature. Also: you skip checksumming. Other's might rant on that lack of feature :-D |
| |
Krill
Registered: Apr 2002
Posts: 2980 |
Quoting BitbreakerAlso: you skip checksumming. Other's might rant on that lack of feature :-D This is indeed rant-worthy and should be a major point of comparison when comparing speeds. While a lack of checksumming doesn't cause much trouble in a lab setting (= at home), in my experience, a party setting with lots and lots of signal interference is a different beast. But then this might just be biased perception (and i haven't conducted scientifically sound tests on that :D). |
| |
chatGPZ
Registered: Dec 2001
Posts: 11386 |
i can atleast say that HCL loader is very bitchy about subtle timing differences, and it will then break because of the missing checksumming :) |
| |
Danzig
Registered: Jun 2002
Posts: 440 |
HCL - Hezno Chagsam Lohda |
| |
HCL
Registered: Feb 2003
Posts: 728 |
Quote:Also: you skip checksumming. Other's might rant on that lack of feature :-D That was an easy one, just hand it out to the checksum top dog (=Krill) and he'll smash it in :P. ..and the ranting continues :D. No, Doynax, there is no place for a standard loader test, what would be doing then all day?!? ;).
Honestly, i can't remember the last time a BoozeDesign demo hanged or crashed in a compo (or ever did?). But it is an unfair compare, yes..
@Groepaz: Are you serious, or did i just mis-interpret that smiley!? |
| |
ChristopherJam
Registered: Aug 2004
Posts: 1409 |
Quote: Quoting ChristopherJamHow many bytes can we snaffle per raster line, and how many cpu-cycles does it take to acquire each byte? If you mean raw transfer power from drive to C-64, my rule of thumb is about 2 bytes per scanline. That is 28 cycles for the actual byte (the usual lda $dd00:lsr:lsr:ora $dd00:... business), times 2, plus a bit of overhead for storing and re-syncing once in a while.
That makes sense for the raw transfer, but I was trying to graph the time including decompression, waiting for data, synchronising etc.
Working assumption was that Bitbreaker's frame counts were for spending 312*(100-load)/100 rasters per frame on loading. Did I get that right? |
| |
Krill
Registered: Apr 2002
Posts: 2980 |
Quoting HCLHonestly, i can't remember the last time a BoozeDesign demo hanged or crashed in a compo (or ever did?). But it is an unfair compare, yes.. Ah, i wasn't thinking about the compo itself, where the machine is run under semi-lab conditions :) Was thinking about C-64s running demos while sitting in row 10, seat 5, at a party like Revision, or in some dark basement with a hundred other C64s, like at Datastorm.. :)
And yes, i took that bait so willingly, it was just hanging so low and an easy bite :D |
| |
Bitbreaker
Registered: Oct 2002
Posts: 508 |
Alright, updated the numbers for BD-loader including viagra, penis-enlargement surgery and cock-ring :-)
And the Frames mean just, that i have a frame counter running, increasing each vsync, so Frames / 50 is loading time in seconds. Then i block the cpu in the irq by wasting another 25/50/75% of the raster time. Screen is on however and of course badlines not spread evenly over the 4 blocks, but acuracy is not that much needed, real drives vary more anyway. E.g. that of THCM gets faster when it is warm, but usually a bit below the benchmarks. |
| |
Bitbreaker
Registered: Oct 2002
Posts: 508 |
On the contrary, removing the checksumming just brings about 5 frames gain in my case, just tried it. But i understand that it is a huge pain in the ass to calculate it with the data scattered over 8 locations (including different offsets and shifts for the decode tables) as with the BD-loader. No fun. Then however, not pulling the whole sector through at once and doing no offline decoding should give an additional 2 frames only. So maybe other things are worth the effort, like serial transfer. |
| |
Frantic
Registered: Mar 2003
Posts: 1648 |
I remember when I was running the LCP 2004 compo and was in the midst of showing the borderline demo by Triad in front of the crowd. Somehow I misread the notes I had on my papers, and I hadn't had the time to check the demo before the actual compo, so I was under the (drunken) impression that this demo was a onefiler. Therefore I thought that I could safely remove the disk from the drive while the demo was running and start preparing for the next demo to show only to notice how Iopop's face turned white, then green, and then raster-bar-striped, and telling me to insert that disk immediately again. So I did, and that fancy loader didn't complain, although I had removed the disk in the middle of actual loading (should have checked the led on the diskdrive eh..). According to the CSDb credits that loader was done by 6R6, so maybe that loader deserves som credits too, for being absolutely foolproof literally. :)
Speaking of checksumming and such, that is.. |
| |
HCL
Registered: Feb 2003
Posts: 728 |
@Frantic: Haha.. i can never imagine you doing such a thing ;)
@Bitbreaker: Wtf, according to latest results, my shit is even a fraction faster than all the other magic loaders when some CPU-load comes into play!??! Can hardly trust those numbers.. I'm not doing anything to be faster than anyone else, except skipping that checksum perhaps :P. I'm using the kernel as much as possible, only optimizing the read-loop and the transfer. On the computer-side i have the new ByteBoozer2, which is on par, but not faster than bitfire. Any explanation!?
One idea i had about ooo was.. to get optimal fetching of sectors perhaps you should prioritize the next sector in the file, since the decruncher might be waiting for it.. Then grabbing any sector on the way there that doesn't cause the high-prio sector to be missed. But perhaps you already do something like that!? |
| |
Bitbreaker
Registered: Oct 2002
Posts: 508 |
Of course yours is faster that way, as all sectors arrive just in time and in order with the right interleave, but this only happens under such straight conditiosn with a fixed load. Imagine with a variable load, you will never be able to have the right interleave and thus miss sectors giving you an extra revolution penalty worstcase. Also have fun calculating the right offset per file and mixing that offset per track that are occupied by different files. See it as the theoretical limit that you neve reach under demo conditions, whereas with ooo, it will reflect real demo conditions. That is why i say it is a bit of cheating. Let me see if i can do a testsituation with a variable load and then lets try again :-D
And yes, i made already tries to priorize the first sector, it performs better if you force the first sector to be block 0 of file, but under load it turns out to be worse again :-D Also increasing allowed distance to next block during loading does not help. Played around a lot with teh barriers, at no avail. All i can do is forcing in order by keeping the max allowed distance between blocks a 1. |
| |
Bitbreaker
Registered: Oct 2002
Posts: 508 |
Ok, quick test: increasing load per frame by one rasterline, best result i can get for your loader is $0a4c frames with interleave 7, wheras bitfire manages that in $09bc frames. That is where ooo hits in. Hard to predict a perfect interleave for in order under such conditions.
And yes, with checksumming it is no problem to just remove the disk and put it back in to make also bitfire and sure others to continue loading, as long as you don't rely on data that should have been loaded meanwhile :-D Floppy fuck! |
| |
Oswald
Registered: Apr 2002
Posts: 5094 |
ooo ? |
| |
Burglar
Registered: Dec 2004
Posts: 1101 |
Quoting Oswaldooo ? Out of Oswald loading of course |
| |
HCL
Registered: Feb 2003
Posts: 728 |
Ok, great now we know the pros and cons.. Thanx Bitbreaker for all the time you put on testing. Think i will settle down now after 5 intense days of csdb postin, and finish that loader/packer system :).
Then sure i'll check out Spindle 2.0 (!) |
| |
Glasnost
Account closed
Registered: Aug 2011
Posts: 26 |
Reading this discussion, i wonder...
- do all loaders in the example have similar timing safety, eg. in stepping tracksm or inner read loop?
- Why are the testfiles so small on average? That gives ooo load (scatterload) a disadvantage in loading while decompressing. |
| |
Oswald
Registered: Apr 2002
Posts: 5094 |
out of order ?:)
I dont understand when you use the term fixed, and when out of order loading. I thought fixed is with fixed interleave what the loader expects, and out of order is a loader which can deal with whatever sector order. but you corrected me, so how is this ? |
| |
Jammer
Registered: Nov 2002
Posts: 1335 |
What Ksubi asked - what about Wegi's solution? His system seems not that popular and maybe it should? ;) |
| |
Oswald
Registered: Apr 2002
Posts: 5094 |
ah, guess its about sector order. |
| |
lft
Registered: Jul 2007
Posts: 369 |
Gentlemen.
While you were entertaining yourselves here, I took the liberty of improving the performance of Spindle.
Details to follow. |
| |
chatGPZ
Registered: Dec 2001
Posts: 11386 |
Quote:@Groepaz: Are you serious, or did i just mis-interpret that smiley!?
nope. your loader/(some of your) demos are the only ones that will not work using chameleons external IEC feature (see here) - and the only sane explanation for that is that the bus timing is very much on the edge (the difference in timing between internal and external is less than a c64 cycle). it might even fail on real drive/c64 when one of the crystals is worn out enough to result in such subtle difference (i have not tested that). (jiffy dos on pal has a similar problem - and there the bus timing is so much on the edge that it barely works even on the real thing) |
| |
Krill
Registered: Apr 2002
Posts: 2980 |
Quoting Glasnost- do all loaders in the example have similar timing safety, eg. in stepping tracksm or inner read loop? I'd assume so. Some intolerances only show randomly after years with certain computer/drive combinations, but i guess all of those loaders have been tested with a reasonable number of device combinations.
Quoting Glasnost- Why are the testfiles so small on average? That gives ooo load (scatterload) a disadvantage in loading while decompressing. Indeed. It's a good idea to load a demo part in one single file, which minimises all sorts of overhead. Lots of small files isn't a realistic test setup for demo performance. |
| |
Bitbreaker
Registered: Oct 2002
Posts: 508 |
Summarizing again:
Out of order loading: Leech in any block that belongs to the file and place it in the right position in c64 mem.
In order: Fetch the blocks in the right order and place them one after another in mem.
Fixed interleave:
When relying to the standard sector layout with a track/sector-link in the beginning of each block, you can't determine which other blocks belong to your file, unless you first scan a whole track and find out, or load one block after another in a serial manner (in order loading again). When you store the files with a fixed interleave on disk you can predict what blocks belong to your file by having the start sector/track + blocklength/filelength at hand. Then, no scanning is necessary. While you are at that you can throw away the track/sector link and use the whole 256 byte of a sector for payload. This also seizes the annoying $fe sectorsize.
I might also give Bongo a try, but am a bit scared by the windows tool coming along with it :-D
As for the fileset i test with, it is most of the files form coma light 13 side 1. First of all, it is demodata, so it should be typical data being used in my preferred scenario. I only threw out a few files that went under io, as not all loaders handle that. Yes, there's small files, and i find that realistic for a demo, not necessarily for a benchmark. Why realistic in a demo setting? Because we tend to fill up gaps beforehand while an effect is on the screen to have less loading during a transition and to keep pace high in that example. I can of course also slap together a bunch of extremely huge Bob parts that fill all mem.
Lft: Good to hear of improvements! :-D |
| |
Oswald
Registered: Apr 2002
Posts: 5094 |
thanks! |
| |
Krill
Registered: Apr 2002
Posts: 2980 |
Quoting BitbreakerYes, there's small files, and i find that realistic for a demo, not necessarily for a benchmark. Why realistic in a demo setting? Because we tend to fill up gaps beforehand while an effect is on the screen to have less loading during a transition and to keep pace high in that example. Okay, i'm sceptical about those gaps, but never mind. But then, would it be possible to have the compressor handle these gaps? Such that you'd link all the small unpacked files and compress to one big file in the end, with all the advantages of minimising loader overhead and maximising pack ratio. (Maybe, at first, exceeding your magical $0200 bytes resident code size limit, as the decompressor will have to add an offset to its output pointer when skipping a gap.) |
| |
Bitbreaker
Registered: Oct 2002
Posts: 508 |
Not in the yet version, but that is what i do in the stream version prototype, having the disk filled with one huge blob, no partly filled sectors, every byte used. Then each block with destination address is fetched from that stream and placed in its respective place in mem. It is bound to in order yet, as no dir and no additional info is needed then. Therefore loading under IO is possible at no extra costs. Size is $131 + $100 buffer.
I btw. updated the numbers for spindle 2.1
Also did a test with huge files. Bitfire performs then at 9,10 kb/s, so it is true that huge files help. Loadraw performance is then at 5,67kb/s. |
| |
Krill
Registered: Apr 2002
Posts: 2980 |
Linking all files to one is one thing, but do you also link before packing? :) |
| |
lft
Registered: Jul 2007
Posts: 369 |
Quoting KrillOkay, i'm sceptical about those gaps, but never mind. But then, would it be possible to have the compressor handle these gaps? Such that you'd link all the small unpacked files and compress to one big file in the end, with all the advantages of minimising loader overhead and maximising pack ratio.
Spindle already does that. When you specify multiple files for a loader call, they are packed end-to-end, with only a single half-filled sector at the end. If you use the pefchain interface, data is automatically split at page boundaries, a global loading schedule is created, and everything that goes into the same loader call is joined at the seams.
The only thing missing is the complete elimination of half-filled sectors, like Bitbreaker suggested. I've had this idea too, but haven't implemented it yet. But it's perfect for pefchain: Currently, all data is loaded as soon as possible, so data "bubbles up" to its earliest possible loading position, getting cut into pieces where necessary. This means that the data chunks will pass several potential loading spots on their way up through the schedule.
My idea is to keep track of all these spots, and mark a chunk as "optional" in any loading spot except its last one. When generating the combined file corresponding to a given loading slot, the cruncher first includes all the mandatory chunks, and then fills up with optional chunks. Afterwards, if the last block is half-filled, it may very well happen that this block contains only optional data. The block is then un-allocated, and the data that went into it is pushed down to its next loading slot in the list.
But, like I said, this is just in the idea stage at the moment. |
| |
Bitbreaker
Registered: Oct 2002
Posts: 508 |
Quote: Out of curiosity... how does Mr Wegi's loader compare to these?
Bongo Linking Engine
I tried it, but i failed so far creating the .inc that contains all the labels so that i can at least address the files from main.asm or alike, and it comes with 32! different loadertypes, with t/s, dir, things, different packers, i'm lost. It seriously lacks documentation and a proper workflow :-( Whereas with spindle, you just smack in the 18 filenames into that script (and wipe out that sidfile being loaded there!1) and call loadnext() from the main file. That's it! While i'm no fan of loaderscripts in demos, i am with benchmarks :-D |
| |
Danzig
Registered: Jun 2002
Posts: 440 |
Just for the sake of it, I would like to see f.e. BETA SKIP IFFL Mastering + Source compared to it. Just name the time used for scanning the iffl file. I would even not count it, since it's an initial process.
And what about file copy (possible? breaks the performance due to changing interleave or "3O"-order ?), random file access (like with a crack) instead of sequential access (demo)? Which system can not offer this features? I know, we are talking about trackmo loader systems, but isn't that narrow minded? Maybe lft and bierkeule can enlighten us, what would be the afford to get that feature and for what cost.
And as GRGs loader was already named, what about comparing with even more loaders (G.I. Joe ;) ). Just to draw a larger scale picture of what Spindle, Bitfire are really capable of. Benchmark is fine, but more reference values would rock. Hey Tobi, Du hast doch so viel Zeit ;)
Even compare it to patched kernal loader ($ee13 SEI moved so you just enter at $ee20. You just loose around �������������������30 rasterlines per frame iirc).
jsr ee13_replace
...
ee13_replace:
LDA #$00
STA $A5
JSR $EE85
JSR $EEA9
BPL *-3
SEI
JMP $ee20
Of course, silly on the one hand, but maybe gives us all a brighter light of what we really have here!? And what other scenarios we might or not be able to realize with these systems.
Thanks for reading, no rant today ;) |
| |
Bitbreaker
Registered: Oct 2002
Posts: 508 |
Ranzig, Du Troll!
It's all written in the results, below the graph is a list of features. Some can only load sequential (load_next) or by filename, others both. Others also can't load the raw file but only load and depack on the fly. Breakage of interleave can't happen due to the use of own d64-creators that support the somewhat custom format. However all still .d64 compatible and easy to copy with a bam copy or disk copy.
Now teach me to open the sideborder again and help me hugging street lights. If those loaders and toolchains are used for quality hacks there's at least the chance that you don't end up with a virus infection (oh wait, that was weasel who managed that). So give it a try! |
| |
chatGPZ
Registered: Dec 2001
Posts: 11386 |
Quote:Now teach me to open the sideborder again
AH! so that is where you stole your demo code! |
| |
Danzig
Registered: Jun 2002
Posts: 440 |
Quote: Ranzig, Du Troll!
It's all written in the results, below the graph is a list of features. Some can only load sequential (load_next) or by filename, others both. Others also can't load the raw file but only load and depack on the fly. Breakage of interleave can't happen due to the use of own d64-creators that support the somewhat custom format. However all still .d64 compatible and easy to copy with a bam copy or disk copy.
Now teach me to open the sideborder again and help me hugging street lights. If those loaders and toolchains are used for quality hacks there's at least the chance that you don't end up with a virus infection (oh wait, that was weasel who managed that). So give it a try!
So, just take some iffl systems, add a row for "iffl" and "file copyable" and put them in compare. Those are also valid trackmo systems aswell. *G* Then I might stfu ;)
And maybe some newbie-friendly explanation so your benchmark can evolve to some reference f.e. to publish on codebase!?
sideborder: take the vic 1 register $9000 to move the screen to the left on even frames and to the right on odd frames. Toggle your bitmap accordingly and you got sideborder even with interlace. Ups, that was VIC 20 and that would look ugly. Hm, sorry, can't fulfill your request. Hugging street lights not possible either anymore, it would bend :D |
| |
Bitbreaker
Registered: Oct 2002
Posts: 508 |
I did a codebase article about it. The inflicted persons may read up and correct/edit/add details if wanted. |
| |
Danzig
Registered: Jun 2002
Posts: 440 |
Quote: Quote:Now teach me to open the sideborder again
AH! so that is where you stole your demo code!
No burglary. He payz just better than Hitmen :D |
| |
chatGPZ
Registered: Dec 2001
Posts: 11386 |
als ob :) |
| |
Fungus
Registered: Sep 2002
Posts: 686 |
And n0sd0s is all stolen from Magnus Lind and everyone else we could steal from, plus my own "shit loader" is largely ripped off from action replay, they all handle sprites and irq and screen off/on, iffl, saving, what the fuck ever and who gives a shit because it does the job and I love you Danzig will you marry me. |
| |
Danzig
Registered: Jun 2002
Posts: 440 |
Quote: And n0sd0s is all stolen from Magnus Lind and everyone else we could steal from, plus my own "shit loader" is largely ripped off from action replay, they all handle sprites and irq and screen off/on, iffl, saving, what the fuck ever and who gives a shit because it does the job and I love you Danzig will you marry me.
Sure? I've been already banged, look :D Belly-2-belly suplex |
| |
Danzig
Registered: Jun 2002
Posts: 440 |
Quote: als ob :)
I remember how Hitmen paid Stan once :D And Bierkeule payz with krabbel-die-wand-nuff.. Easier to cope with! |
| |
Krill
Registered: Apr 2002
Posts: 2980 |
Quoting lftQuoting KrillOkay, i'm sceptical about those gaps, but never mind. But then, would it be possible to have the compressor handle these gaps? Such that you'd link all the small unpacked files and compress to one big file in the end, with all the advantages of minimising loader overhead and maximising pack ratio. Spindle already does that. When you specify multiple files for a loader call, they are packed end-to-end, with only a single half-filled sector at the end Doesn't Spindle only pack on a per-block basis? If so, this would mean no difference for the pack ratio and pretty much invalidate my question. Or DOES Spindle compress dictionary-based, so packing more data for a single load results in better pack ratio, many files or no? :) |
| |
Burglar
Registered: Dec 2004
Posts: 1101 |
im still hoping bitbreaker will add amount of blocks used on disk for each loader+packer someday.
but I think I read in lft's docs that he allows using already uncrunched data, if it was loaded from a previous track (and therefore must be there already), but i'm sure he will enlighten us ;)
edit:
Quote:All the data for a particular loading slot is compressed into a set of
sectors, such that each sector can be decompressed individually. The cruncher
is an optimal-path LZ packer (based on dynamic programming) that stops as soon
as the crunched data fills a disk block. Every sector contains a number of
independent units, each comprising a destination address, the number of
"pieces" of crunched data, a bit stream and a byte stream. Because the
crunched data fits in a sector, the indices into these streams are 8-bit
quantities, which speeds up the decrunching. Immediately after a track
boundary, blocks may also refer to data that was loaded earlier. |
| |
Bitbreaker
Registered: Oct 2002
Posts: 508 |
Quoting Burglarim still hoping bitbreaker will add amount of blocks used on disk for each loader+packer someday.
Not necessary, as i used bitnax in the krill and bitfire example and bb2 packs at the same rate :-D However the loaders using standard files have only 254 byte payload per block, so they might end up in using a very few more blocks. I could also just supply .d64 files of each test. The only one that differs is Spindle, the extra blocks have been named somewhere up in that thread.
The hint from Krill sounds interesting, so when i split files due to not loading under IO i might of course reference stuff that i loaded and unpacked before below $d000. I'll see what i can squeeze out there. |
| |
Burglar
Registered: Dec 2004
Posts: 1101 |
err yes ;) so ~391 blocks for all except spindle that's 25% bigger with 491 blocks. quite a large amount to be fastest :) |
| |
Bitbreaker
Registered: Oct 2002
Posts: 508 |
It's 457 blocks being used in the spindle example (2.1 that is which packs a bit better now). Loading blocks faster and therefore more isn't bringing the gain (compare the loadraw values with packed data and raw data were available), it is the depacker (nothing piles up and is finished after loading like in my case, where then oading stalls for a moment) and having the blocks now faster at hand due to preloading. That would be my guess. |
| |
Burglar
Registered: Dec 2004
Posts: 1101 |
thats quite a big improvement! A "Good work!" for lft :P
in terms of packed size, it'd be interesting (for me lol) if you added krill + exomizer to the benchmark ;) |
