| |
Krill
Registered: Apr 2002
Posts: 3103 |
Release id #214940 : TSCrunch
Quoting tonysavon"TSCrunch is an optimal, byte-aligned, LZ+RLE hybrid encoder, designed to maximize decoding speed on NMOS 6502 and derived CPUs, while achieving decent compression ratio (for a bytecruncher, that is). It crunches as well as other popular bytecrunchers, while being considerably faster at decrunching."
[...]
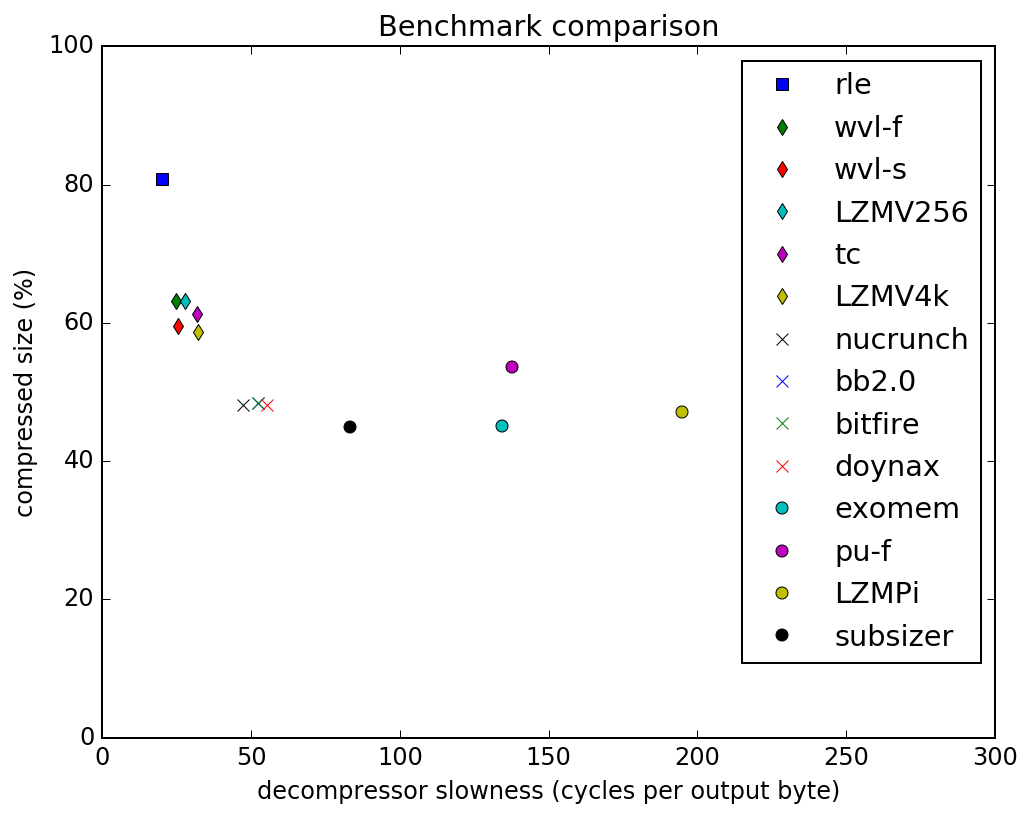
TSCrunch is a bytepacker, with 2byte RLE, 1-2byte LZ tokens and a 512 bytes search window. In this "space" it provides the optimal solution to the puzzle. Exomizer is s different beast, being a bit-cruncher. According to these specs, i'd expect it to fall somewhere into the 60% cluster in the graph below, from https://codebase64.org/doku.php?id=base:compression_benchmarks.
If it is made for in-memory decompression of data, can it also work with prefix data for better compression, i.e., back-referencing to data already in memory (either a static dictionary or, e.g., the previous level)?
And i can't quite follow what "bit-cruncher" vs "byte-cruncher" means. :)
IIRC, Exomizer works on byte-aligned source data as well, also with LZ and RLE.
It produces a bit-stream on the control symbols, though, which is interleaved with byte-aligned literals.
A "bit-cruncher" might maybe be something LZMA- or ANS-like (think ALZ64, or Shrinkler on Amiga), but not Exomizer.
 |
|
... 31 posts hidden. Click here to view all posts....
|
| |
Krill
Registered: Apr 2002
Posts: 3103 |
Can you add ZX0 (aka Salvador aka Dali) for reference? :)
(Bitbreaker's variant with a 6502-optimised bitstream would probably perform best.)
It's a strong contender to Exomizer in terms of crunchiness, but decompresses so much faster. |
| |
tonysavon
Registered: Apr 2014
Posts: 27 |
Quote: Can you add ZX0 (aka Salvador aka Dali) for reference? :)
(Bitbreaker's variant with a 6502-optimised bitstream would probably perform best.)
It's a strong contender to Exomizer in terms of crunchiness, but decompresses so much faster.
Yes! I'm a big fan of zx0/Dali and I already "ported" bitbreaker's optimized version to Kickassembler. I'll post results later today when off work. |
| |
tonysavon
Registered: Apr 2014
Posts: 27 |
I added dali data. It's really a fantastic cruncher, definitely the most balanced one: you kinda get the best of the two worlds!
BTW, In my game I'm using dali for code crunching (where I need the best compression), and TSCrunch for level crunching, because the faster the better in that case, and I can tolerate some % crunching penalty if I can decrunch twice as fast than with Dali. The sample file I'm using for this benchmark (the prg for the game Chopper Command) has a bit of everything (code, music, gfx, a KLA, tables etc.). So I think it represents a nice testbed.
I tried to post raw numbers here, but the preview messes up the spacing in the tables, so the data becomes unreadable.
The graph should tell enough though.
 |
| |
Krill
Registered: Apr 2002
Posts: 3103 |
I think i should add TSCrunch to the loader, too, in the "recommended for demos" section along ZX0, tinycrunch, Bitnax and LZSA2. :)
But for that, in-place decompression is required.
(It's not required for the loadcompd call per se, but for the "demo-friendly" label.)
Basically, this just means stopping decompression a little before the end of data, and having the final incompressible piece of data already there.
(Along with forward-decrunching and slapping on the correct load address for the compressed data, so both incarnations end at the same address.)
It's on your to-do list as per readme, when do you reckon could you spare the time to add it? :)
Oh and for future graphs, consider inverting the "% of original (lower is better)" to "% of original saved (higher is better)" so higher is better on all of them (saves one brain-indirection when looking at those graphs). =) |
| |
Burglar
Registered: Dec 2004
Posts: 1139 |
yay, loader benchmarks \o/
@tonysavon: can you use a smaller diagram size? this does not fit the screen (both in width and height). 40% of the current size would be good :) |
| |
Krill
Registered: Apr 2002
Posts: 3103 |
Quoting Burglaryay, loader benchmarks \o/ The graphs are for pure de/crunch performance without loading, though. :)
But TSCrunch seems to go towards memcpy throughput even more than tinycrunch, and thus is a good candidate to completely decrunch a loaded block before the next one rolls in. |
| |
tonysavon
Registered: Apr 2014
Posts: 27 |
@Burglar I've made the picture smaller, hopefully readable.
@Krill, indeed, that's exactly the purpose of this cruncher. It was designed to stream-uncrunch data as quickly as possible, be it from a disk (once you add it to Krill, which would be a-m-a-z-i-n-g), or cartridge which is how I currently use it. For my purposes I needed to stay below 20 cycles per output byte, in the general case (then of course some nasty sequences might clock in at a bit more than that, but usually it averages at 18 cycles per byte), and no cruncher other than simple RLE would give me that performance, so I had to get my hands dirty. It'd be really nice if you could test it with Krill loader already and see how loadcmpd performs. I'll be adding inplace decrunching anyway over the weekend, hopefully.
Thanks everyone for the feedback.
 |
| |
Krill
Registered: Apr 2002
Posts: 3103 |
Quoting tonysavonand see how loadcmpd performs. I'll be adding inplace decrunching anyway over the weekend, hopefully. Great!
I've been heavily refactoring and cleaning up everything on the host side, and adding a new decruncher is now done in an hour or two. =)
Still need to solve some other puzzles until the next release, but it'll be exciting to see how TSCrunch performs with the Bitfire and Spindle benchmarks. (Now also a part of the source package, and ZX0 comes out on top.) |
| |
Burglar
Registered: Dec 2004
Posts: 1139 |
Quoting tonysavon@Burglar I've made the picture smaller, hopefully readable. thank you! :) also good you have a throughput graph, when crunchers are this close in compression, throughput is what matters most. |
| |
Krill
Registered: Apr 2002
Posts: 3103 |
Quoting Burglarwhen crunchers are this close in compression, throughput is what matters most. Indeed! And in conjunction with loading, there's probably a magic throughput/compression ratio thingy so a block is just barely but still fully decrunched before the next one rolls in, and the ratio good enough so there are not so many more blocks overall than for something hard-core like Exomizer. :) |
| Previous - 1 | 2 | 3 | 4 | 5 - Next |
