Krill
Registered: Apr 2002
Posts: 3083 |
Release id #214940 : TSCrunch
Quoting tonysavon"TSCrunch is an optimal, byte-aligned, LZ+RLE hybrid encoder, designed to maximize decoding speed on NMOS 6502 and derived CPUs, while achieving decent compression ratio (for a bytecruncher, that is). It crunches as well as other popular bytecrunchers, while being considerably faster at decrunching."
[...]
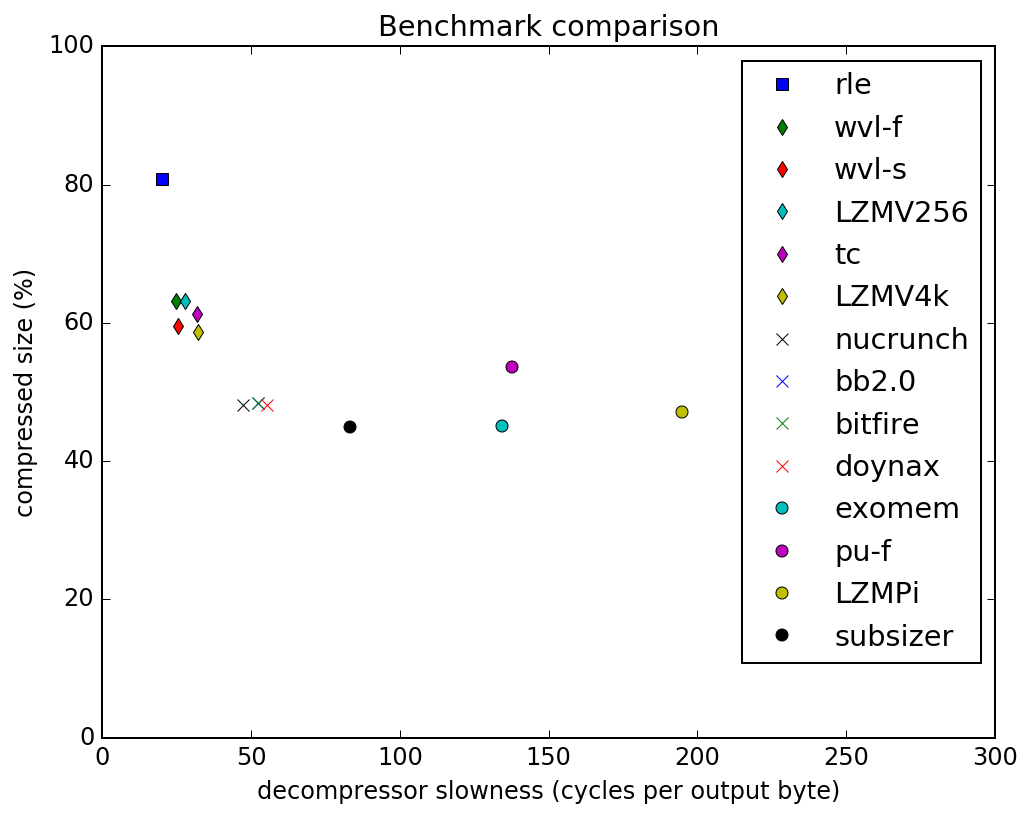
TSCrunch is a bytepacker, with 2byte RLE, 1-2byte LZ tokens and a 512 bytes search window. In this "space" it provides the optimal solution to the puzzle. Exomizer is s different beast, being a bit-cruncher. According to these specs, i'd expect it to fall somewhere into the 60% cluster in the graph below, from https://codebase64.org/doku.php?id=base:compression_benchmarks.
If it is made for in-memory decompression of data, can it also work with prefix data for better compression, i.e., back-referencing to data already in memory (either a static dictionary or, e.g., the previous level)?
And i can't quite follow what "bit-cruncher" vs "byte-cruncher" means. :)
IIRC, Exomizer works on byte-aligned source data as well, also with LZ and RLE.
It produces a bit-stream on the control symbols, though, which is interleaved with byte-aligned literals.
A "bit-cruncher" might maybe be something LZMA- or ANS-like (think ALZ64, or Shrinkler on Amiga), but not Exomizer.
 |
