| |
ChristopherJam
Registered: Aug 2004
Posts: 1409 |
Decrunch direction
So I'm in the middle of updating nucrunch's self extracting file generator to change over to the two-segment no-copy forward decrunch method I pioneered in tinycrunch. The forward decruncher is slightly faster than the reverse, and the two segment method should also make it easer to add support for lowering the minimum start address to 0x0200.
I was just wondering if there was any point in maintaining the reverse decruncher at all - if I drop it, then I can simplify the code somewhat, and maintenance will be saner moving forward. I pretty much only implemented it for SFX purposes, and that requirement is gone now.
Any thoughts?
Definitions:
A forward decrunch reads the input data from the start to the end, and also outputs in the same direction. A reverse decrunch starts from the end of the input data and works backward, and does the same with the output. It's handy for traditional single-segment self extracting files as you don't have to copy the input to high memory before you start decrunching.
Two segment method: two segment SFXes contain two chunks of data - the first decompresses to the area of RAM starting at the end of the loaded data, and the rest is an in-place compressed copy of the rest.
eg
before decrunch: ........daaaaaaaabbbbbb......................
after decrunch: ..d...BBBBBBBBBBBBBBBBBAAAAAAAAAAAAAAAAAAA...
where
- a is a compressed copy of the data at A
- b is a compressed copy of the data at B
- d is the decruncher (which copies itself to low memory before executing.) |
|
| |
tlr
Registered: Sep 2003
Posts: 1790 |
Pretty nifty, but how do you handle back references from stream b into data A? |
| |
ChristopherJam
Registered: Aug 2004
Posts: 1409 |
Thanks!
I don't, they're compressed independently - but in practice that only inflates the compressed data by one or two dozen bytes. |
| |
ChristopherJam
Registered: Aug 2004
Posts: 1409 |
…so, no one actually uses reverse decrunch for anything outside SFXes then? |
| |
Trash
Registered: Jan 2002
Posts: 122 |
Quote: …so, no one actually uses reverse decrunch for anything outside SFXes then?
That would be weird, loading a file where it is supposed to be unchrunched seems much more efficient than allocating space for both the unchrunched file and the chrunched file... |
| |
ChristopherJam
Registered: Aug 2004
Posts: 1409 |
That's somewhat orthogonal, Trash. If you're loading to one place and decruching to another (as one might if (eg) preloading the next demo part to high memory, and decrunching over the previous part when switching to it), then the decrunch direction is irrelevant.
Where it does matter, is if you're loading into the destination space. Forward decrunch, and you need to load into the end of the space, reverse, and you load into the start of the space.
I should make some graphs :-/ |
| |
Krill
Registered: Apr 2002
Posts: 2980 |
Yes, decrunch direction is only tied to loading direction, and then only when decrunching in-place while loading. That said, reverse loading would be even weirder than reverse decrunch already is. :)
As for thoughts:
Yes, do get rid of reverse decrunch if you can. It wasn't the best idea from the start due to more cycles for hi-byte handling, thus slightly slower than clean forward decrunch. And with your invention of 2-segment decrunching, the copying overhead which backward decrunch is supposed to counter is not relevant any more. Also, fewer test cases are always a good idea.
Only downside would be those few dozen bytes of worse packing ratio, but those only come into play if you're plotting to de-throne Exomizer in terms of packing ratio. (It was always on the slower side, so speed isn't an issue there.) |
| |
ChristopherJam
Registered: Aug 2004
Posts: 1409 |
(I just realised Trash may have read my "outside" as referring to disjoint memory areas. My apologies if so - I meant "use cases other than") |
| |
ChristopherJam
Registered: Aug 2004
Posts: 1409 |
Ok, looks like I'll be doing a code cleanout.
As for the small impact on compressed data size, looks like I more than gain that back in code size - the forward decrunch routine is about 60 bytes smaller :D |
| |
Krill
Registered: Apr 2002
Posts: 2980 |
Be afraid, Exomizer, be VERY afraid. :) |
| |
Oswald
Registered: Apr 2002
Posts: 5094 |
Quote: That would be weird, loading a file where it is supposed to be unchrunched seems much more efficient than allocating space for both the unchrunched file and the chrunched file...
in a demo usually you dont have free space, when an effect runs and you also load, at the designated decrunch location. |
| |
Mixer
Registered: Apr 2008
Posts: 452 |
So, with forward decrunch the crunched file must be loaded to the (end of allocated space - sizeof decrunch file)?
Or does the decruncher do the transfer to the end of space?
If then, one needs to know the size of compressed file to be able to set the load address to the right location.
Isn't this just transfering some operations off of the decruncher to whatever code uses the packed file? |
| |
Krill
Registered: Apr 2002
Posts: 2980 |
Quoting MixerSo, with forward decrunch the crunched file must be loaded to the (end of allocated space - sizeof decrunch file)? Yes. If you mean (end of allocated space - sizeof crunched file).
Quoting MixerOr does the decruncher do the transfer to the end of space? No. That copy is to be avoided (as it isn't done for classic backward decrunching, which has been used to avoid that copy).
Quoting MixerIf then, one needs to know the size of compressed file to be able to set the load address to the right location. That's what the cruncher would do, assign the right loading address for the crunched data file.
Quoting MixerIsn't this just transfering some operations off of the decruncher to whatever code uses the packed file? Not really, the idea is to avoid copying packed data while still getting that bit of extra speed forward decrunching provides over backward decrunching. In the scenario of loading packed files (rather than running an SFX), the load address is good for forward decrunching, which the loader would then proceed to do while loading. |
| |
bubis
Account closed
Registered: Apr 2002
Posts: 19 |
Wow, this two segment method is a brilliant idea! You should patent it! :D |
| |
ChristopherJam
Registered: Aug 2004
Posts: 1409 |
Thanks Bubis! Re. patents, haha probably.
Some diagrams to illustrate my comments above:
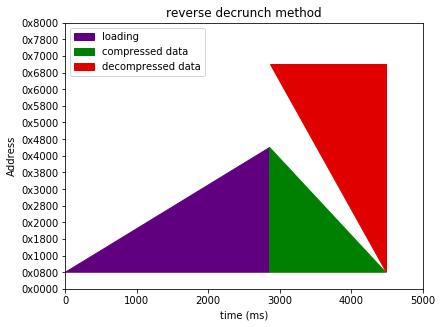
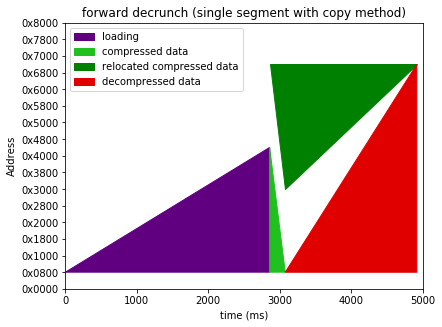
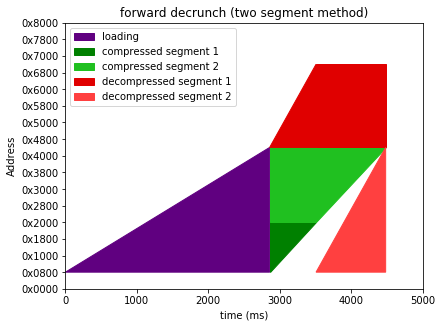
I've elided the decrunch code space allocation and copying time, (they're pretty minimal), and assumed
- a destination area that starts from ~$0800
- an initial data load to $0801 (as is required for anything with a sysline)
- decrunch doesn't start until after loading (no other option for onefilers)
- a three block interleave fastload (just so I don't swamp the graphs with load time)
- a 60% compression ratio
I've also assumed identical decompression speed for forward and reverse decrunch. Going back over my old benchmarks the two nucrunch decoders turn out to be much of a muchness; sometimes one is 1-2% faster, sometimes the other. I'm still dropping the reverse codec mind; as much as anything else I need to switch to either copy+decrunch or multisegment just to support destinations below $0800. |
| |
Mixer
Registered: Apr 2008
Posts: 452 |
Awesome space-time graphs. |
| |
Copyfault
Registered: Dec 2001
Posts: 478 |
Cool idea doing a split up of the data sequence! However, this should arise some questions, e.g. how to find the best "split point" of the complete (unpacked) data sequence, wether it makes sense to have even more segments, etc...
Quoting ChristopherJam [...]
Two segment method: two segment SFXes contain two chunks of data - the first decompresses to the area of RAM starting at the end of the loaded data, and the rest is an in-place compressed copy of the rest.
eg
before decrunch: ........daaaaaaaabbbbbb......................
after decrunch: ..d...BBBBBBBBBBBBBBBBBAAAAAAAAAAAAAAAAAAA...
where
- a is a compressed copy of the data at A
- b is a compressed copy of the data at B
- d is the decruncher (which copies itself to low memory before executing.)
Just a thought about the decruncher code: you could avoid copying this if the decruncher is placed at the end of the crunched data chunk, i.e.
before decrunch: ........aaaaaaaabbbbbbd......................
which should allow to decrunch to the lower mem locations without hassle, like
after decrunch: ..BBBBBBBBBBBBBBBBBBBBdAAAAAAAAAAAAAAAAAAA...
Depending on the inner workings of the decruncher it might even be possible to "overwrite" it in the 2nd decrunch phase as I can imagine that having the decruncher code in the middle of the decrunched data is not wanted in most cases.
Should speed up the overall decrunch speed a little and widen the memory location for the decrunched data. Just some thought that came to my mind reading about this !!brilliant!! two segment decrunch method... |
| |
ChristopherJam
Registered: Aug 2004
Posts: 1409 |
Thanks for feedback all.
As for split point determination, tinycrunch currently does a first pass where it compresses the entire input file to get an estimate of the end-of-load address, then does a few trial iterations until the intersegment gap is reasonably small (cf TinyCrunch V1.1.1 source for details; run in verbose mode to see the iterations in action).
I am indeed considering placing the default ("medium") nucrunch decoder at the splitpoint for the next release, probably with a tinycrunch decoder copied to the stack for decrunching the medium decrunch routine at start of decrunch, then infilling the gap once the bulk of data has been decrunched.
But yes, ideally I'd place the primary decompressor somewhere where the final file just has a run of zeros or some other easy to reproduce data. A feature for another day, when I get around to putting the final cleanup code in the sprite position registers like that other all memory decruncher whose name currently escapes me. |
| |
Radiant
Registered: Sep 2004
Posts: 639 |
Simple. Smart. |
| |
Oswald
Registered: Apr 2002
Posts: 5094 |
first time I just skimmed through the first post, but if bubis says something is brilliant, I must check, and it is ;) |
