| |
Krill
Registered: Apr 2002
Posts: 3098 |
Release id #214940 : TSCrunch
Quoting tonysavon"TSCrunch is an optimal, byte-aligned, LZ+RLE hybrid encoder, designed to maximize decoding speed on NMOS 6502 and derived CPUs, while achieving decent compression ratio (for a bytecruncher, that is). It crunches as well as other popular bytecrunchers, while being considerably faster at decrunching."
[...]
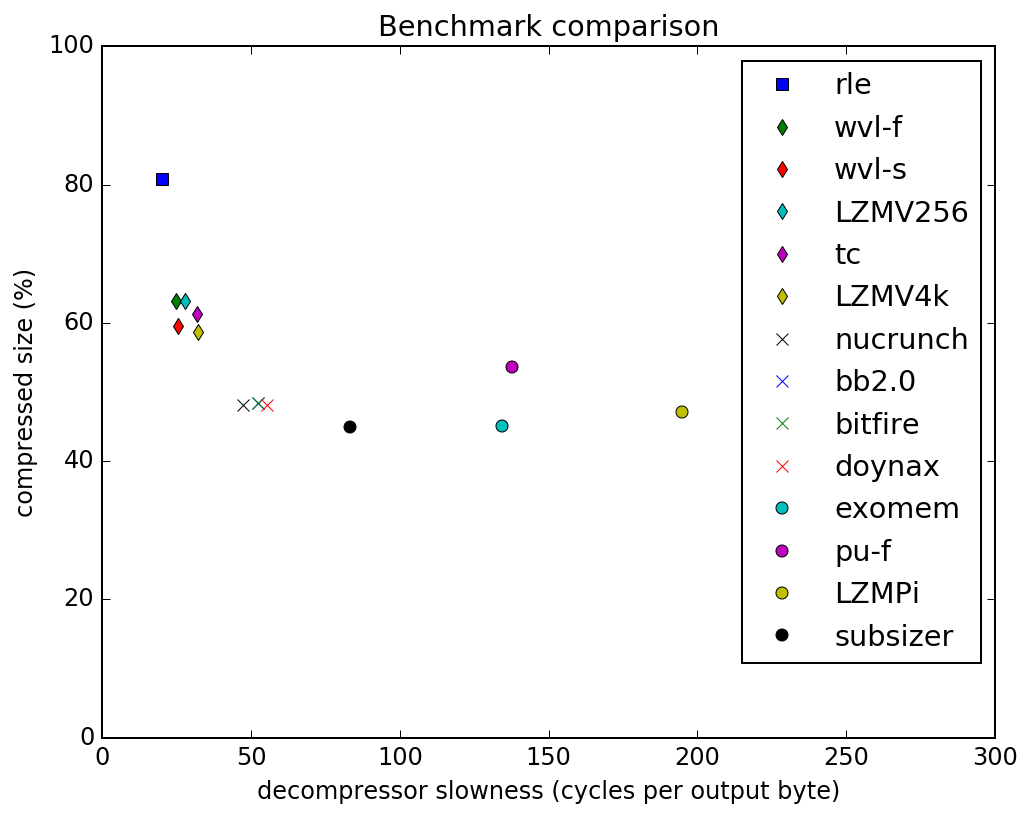
TSCrunch is a bytepacker, with 2byte RLE, 1-2byte LZ tokens and a 512 bytes search window. In this "space" it provides the optimal solution to the puzzle. Exomizer is s different beast, being a bit-cruncher. According to these specs, i'd expect it to fall somewhere into the 60% cluster in the graph below, from https://codebase64.org/doku.php?id=base:compression_benchmarks.
If it is made for in-memory decompression of data, can it also work with prefix data for better compression, i.e., back-referencing to data already in memory (either a static dictionary or, e.g., the previous level)?
And i can't quite follow what "bit-cruncher" vs "byte-cruncher" means. :)
IIRC, Exomizer works on byte-aligned source data as well, also with LZ and RLE.
It produces a bit-stream on the control symbols, though, which is interleaved with byte-aligned literals.
A "bit-cruncher" might maybe be something LZMA- or ANS-like (think ALZ64, or Shrinkler on Amiga), but not Exomizer.
 |
|
| |
tonysavon
Registered: Apr 2014
Posts: 27 |
Hi Krill,
Thanks for giving TSCrunch a go! I'm flattered :-)
I think it's my bad in rushing out the post and the terminology not being so clear as a result. By byte-cruncher I mean crunchers that have fixed-size tokens, multiple of a byte, while other crunchers might rely on (elias) gamma coding to work with integers whose range is not known a-priory. The latter approach yields better crunching but of course the bitstream becomes more difficult to manage, hence the slow decompression.
So, looking at your graph, you are right: TSCrunch belongs to the "family" of TC, WVL and LZW, but it should be faster at decrunching in general.
Whether it crunches better than TC depends on the type of data that you are crunching: TC has a wider lookback window, but it doesn't explicitly manage RLE (I think). So this usually translates to TC crunching a bit better if the repeated patterns are quite far apart and there are not many same byte sequences, while TSCrunch should crunch better for the remaining cases. I don't know what data is used in that benchmark, but I ran many experiments myself (plus TSCrunch has been quietly used by few beta testers in their productions) using only TSCrunch, B2 and TC (for my needs speed is the most important aspect), and for real case scenarios on large files it seems that TSCrunch behaves better also from the point of view of crunching %.
This graph shows figures for memcrunching a game (chopper command). The data is in the readme.txt, but you can take a look at this picture for performance at a glance.
 |
| |
Krill
Registered: Apr 2002
Posts: 3098 |
Can you add ZX0 (aka Salvador aka Dali) for reference? :)
(Bitbreaker's variant with a 6502-optimised bitstream would probably perform best.)
It's a strong contender to Exomizer in terms of crunchiness, but decompresses so much faster. |
| |
tonysavon
Registered: Apr 2014
Posts: 27 |
Quote: Can you add ZX0 (aka Salvador aka Dali) for reference? :)
(Bitbreaker's variant with a 6502-optimised bitstream would probably perform best.)
It's a strong contender to Exomizer in terms of crunchiness, but decompresses so much faster.
Yes! I'm a big fan of zx0/Dali and I already "ported" bitbreaker's optimized version to Kickassembler. I'll post results later today when off work. |
| |
tonysavon
Registered: Apr 2014
Posts: 27 |
I added dali data. It's really a fantastic cruncher, definitely the most balanced one: you kinda get the best of the two worlds!
BTW, In my game I'm using dali for code crunching (where I need the best compression), and TSCrunch for level crunching, because the faster the better in that case, and I can tolerate some % crunching penalty if I can decrunch twice as fast than with Dali. The sample file I'm using for this benchmark (the prg for the game Chopper Command) has a bit of everything (code, music, gfx, a KLA, tables etc.). So I think it represents a nice testbed.
I tried to post raw numbers here, but the preview messes up the spacing in the tables, so the data becomes unreadable.
The graph should tell enough though.
 |
| |
Krill
Registered: Apr 2002
Posts: 3098 |
I think i should add TSCrunch to the loader, too, in the "recommended for demos" section along ZX0, tinycrunch, Bitnax and LZSA2. :)
But for that, in-place decompression is required.
(It's not required for the loadcompd call per se, but for the "demo-friendly" label.)
Basically, this just means stopping decompression a little before the end of data, and having the final incompressible piece of data already there.
(Along with forward-decrunching and slapping on the correct load address for the compressed data, so both incarnations end at the same address.)
It's on your to-do list as per readme, when do you reckon could you spare the time to add it? :)
Oh and for future graphs, consider inverting the "% of original (lower is better)" to "% of original saved (higher is better)" so higher is better on all of them (saves one brain-indirection when looking at those graphs). =) |
| |
Burglar
Registered: Dec 2004
Posts: 1137 |
yay, loader benchmarks \o/
@tonysavon: can you use a smaller diagram size? this does not fit the screen (both in width and height). 40% of the current size would be good :) |
| |
Krill
Registered: Apr 2002
Posts: 3098 |
Quoting Burglaryay, loader benchmarks \o/ The graphs are for pure de/crunch performance without loading, though. :)
But TSCrunch seems to go towards memcpy throughput even more than tinycrunch, and thus is a good candidate to completely decrunch a loaded block before the next one rolls in. |
| |
tonysavon
Registered: Apr 2014
Posts: 27 |
@Burglar I've made the picture smaller, hopefully readable.
@Krill, indeed, that's exactly the purpose of this cruncher. It was designed to stream-uncrunch data as quickly as possible, be it from a disk (once you add it to Krill, which would be a-m-a-z-i-n-g), or cartridge which is how I currently use it. For my purposes I needed to stay below 20 cycles per output byte, in the general case (then of course some nasty sequences might clock in at a bit more than that, but usually it averages at 18 cycles per byte), and no cruncher other than simple RLE would give me that performance, so I had to get my hands dirty. It'd be really nice if you could test it with Krill loader already and see how loadcmpd performs. I'll be adding inplace decrunching anyway over the weekend, hopefully.
Thanks everyone for the feedback.
 |
| |
Krill
Registered: Apr 2002
Posts: 3098 |
Quoting tonysavonand see how loadcmpd performs. I'll be adding inplace decrunching anyway over the weekend, hopefully. Great!
I've been heavily refactoring and cleaning up everything on the host side, and adding a new decruncher is now done in an hour or two. =)
Still need to solve some other puzzles until the next release, but it'll be exciting to see how TSCrunch performs with the Bitfire and Spindle benchmarks. (Now also a part of the source package, and ZX0 comes out on top.) |
| |
Burglar
Registered: Dec 2004
Posts: 1137 |
Quoting tonysavon@Burglar I've made the picture smaller, hopefully readable. thank you! :) also good you have a throughput graph, when crunchers are this close in compression, throughput is what matters most. |
| |
Krill
Registered: Apr 2002
Posts: 3098 |
Quoting Burglarwhen crunchers are this close in compression, throughput is what matters most. Indeed! And in conjunction with loading, there's probably a magic throughput/compression ratio thingy so a block is just barely but still fully decrunched before the next one rolls in, and the ratio good enough so there are not so many more blocks overall than for something hard-core like Exomizer. :) |
| |
Dano
Registered: Jul 2004
Posts: 242 |
Gave it a spin on one of my unreleased anim parts.
For 64 frames of screen and colorram it packs $200 bytes than TinyCrunch. Nice one!
And looking at the mem in C64Debugger it looks noticeably faster.
Great release! |
| |
Krill
Registered: Apr 2002
Posts: 3098 |
Quoting DanoGave it a spin on one of my unreleased anim parts. Sorry for slight off-topic-ness, but... i always wonder if using a non-lossy general-purpose compressor is the right choice for media content. :) |
| |
Dano
Registered: Jul 2004
Posts: 242 |
Depends on what you feed it with and things. Sometimes you want things to be lossless. Sometimes you just want to see where you get with a shovel and hammer. |
| |
ChristopherJam
Registered: Aug 2004
Posts: 1424 |
Great work Tony, it looks like it fits your use case really well.
As you suspected, TinyCrunch has no explicit support for RLE, and performs pretty abysmally on any data with large empty spaces - the maximum match length is 17 bytes, and it uses a two byte token for any matches longer than two bytes, so the compression ratio is capped to 8.5. My own speed demon's on hold for the moment, but as I mentioned on FB, yours will be an interesting one to try and best :) |
| |
Krill
Registered: Apr 2002
Posts: 3098 |
Quoting tonysavonFor my purposes I needed to stay below 20 cycles per output byte, in the general case Could you give a figure for average cycles per input byte? :)
(This is the relevant number to estimate whether a block can be fully decrunched until the next block is received.) |
| |
tonysavon
Registered: Apr 2014
Posts: 27 |
Quote: Quoting tonysavonFor my purposes I needed to stay below 20 cycles per output byte, in the general case Could you give a figure for average cycles per input byte? :)
(This is the relevant number to estimate whether a block can be fully decrunched until the next block is received.)
Sure.
In this metric, if you crunch better you do worse, I guess, because there are fewer bytes to read at the denominator, but this is what I get for Chopper Command amyway:
Total decrunch cycles:
TSCrunch: 799826
TC: 1133039
Dali: 1436401
Crunched file size:
TSCrunch: 13321
TC: 15419
Dali: 10478
Cycles per output byte:
TSCrunch: 17.0
TC: 24.1
Dali: 36.1
Cycles per input byte:
TSCrunch: 60.0
TC: 73.5
Dali: 137.1
|
| |
tonysavon
Registered: Apr 2014
Posts: 27 |
Quote: Great work Tony, it looks like it fits your use case really well.
As you suspected, TinyCrunch has no explicit support for RLE, and performs pretty abysmally on any data with large empty spaces - the maximum match length is 17 bytes, and it uses a two byte token for any matches longer than two bytes, so the compression ratio is capped to 8.5. My own speed demon's on hold for the moment, but as I mentioned on FB, yours will be an interesting one to try and best :)
Well, I'm definitely looking forward to whatever you'll release, especially with that amazing name you chose! :-)
TC is such a nice packer btw, now that I'm looking more and more at it. Lots of clever solutions, and I especially love the two-parts sfx decdunching. Plus all the options it comes with...
Keep up the good working! |
| |
tonysavon
Registered: Apr 2014
Posts: 27 |
All right, I added inplace decrunching, so now it's up to you, @Krill :-)
I'll wait a bit before I bump the version here on CSDb as well, but in the meantime you can download version 1.1 from here:
https://github.com/tonysavon/TSCrunch |
| |
Krill
Registered: Apr 2002
Posts: 3098 |
Quoting tonysavonAll right, I added inplace decrunching, so now it's up to you, @Krill :-) Alright, a few first numbers from the WIP next loader version. =)CPU% ZX0 TS WIN
100 9953 9744 ZX0
90 9086 9437 TS
80 7147 7054 ZX0
70 6222 6328 TS
60 5538 5670 TS
50 4706 4685 ZX0
40 4017 4359 TS
30 3000 3432 TS
20 2030 2404 TS
10 929 1126 TS Bitfire benchmark, numbers are throughput in decrunched bytes per second, higher is better.
Both TSCrunch and ZX0 are quite close to each other, but at just under 50% or less CPU for loading/decrunching, TSCrunch shows its strengths over ZX0.
This matters a lot in a real-world scenario where things are going on while loading in the background. |
| |
tonysavon
Registered: Apr 2014
Posts: 27 |
Quote: Quoting tonysavonAll right, I added inplace decrunching, so now it's up to you, @Krill :-) Alright, a few first numbers from the WIP next loader version. =)CPU% ZX0 TS WIN
100 9953 9744 ZX0
90 9086 9437 TS
80 7147 7054 ZX0
70 6222 6328 TS
60 5538 5670 TS
50 4706 4685 ZX0
40 4017 4359 TS
30 3000 3432 TS
20 2030 2404 TS
10 929 1126 TS Bitfire benchmark, numbers are throughput in decrunched bytes per second, higher is better.
Both TSCrunch and ZX0 are quite close to each other, but at just under 50% or less CPU for loading/decrunching, TSCrunch shows its strengths over ZX0.
This matters a lot in a real-world scenario where things are going on while loading in the background.
That's really cool, Krill. Thanks for integrating it so quickly.
These figures seems to validate the hypothesis that it's not just about extreme speed and extreme compression, but mostly about finding the sweet spot. When the loader/decruncher has all the CPU time for itself, then better compression has an impact, but as you start doing something at the same time than speed helps.
It's really fascinating from an analytical standpoint, as there are so many variables involved and it'll be really difficult to find a cruncher (or even a benchmark) to rule them all. |
| |
Bitbreaker
Registered: Oct 2002
Posts: 510 |
It shows again, that the loader usually is the bottleneck, and it has data steadily available to transfer on higher CPU loads, as the floppy can keep up. The bottleneck is also becoming oobvious as TS should perform way better when seeing the plain depack speed figures. Observed the same when comparing zx0 with bitnax, it yields better speed and ratio, but figures for loadcomp do not increase as much as plain decomp. That is why i decided to go for ration instead of a speedgain, as you pay that by lots of blocks, and precious diskspace is also a thing to keep an eye on with demos. zx0 gives 121 free extra blocks when applied to c=bit'18. |
| |
Sparta
Registered: Feb 2017
Posts: 52 |
Great cruncher, @Tony and promising numbers indeed, @Krill. :) Are these from real HW of VICE? Can you please share the total number of frames required to load the whole benchmark for each cruncher (100% CPU availability would do it). Thanks! |
| |
Krill
Registered: Apr 2002
Posts: 3098 |
Quoting SpartaAre these from real HW of VICE? Can you please share the total number of frames required to load the whole benchmark for each cruncher (100% CPU availability would do it). Thanks! VICE, i just needed some numbers quickly. =)
Equivalent figures with number of video frames:CPU% ZX0 TS WIN
100 03a4 03b8 ZX0
90 03fd 03d7 TS
80 0512 0523 ZX0
70 05d3 05ba TS
60 068b 0664 TS
50 07b3 07bc ZX0
40 0905 0850 TS
30 0c14 0a8f TS
20 11da 0f12 TS
10 2702 202b TS Formula to get troughput as above is 185526 * 50 / numframes = X B/s. |
| |
Sparta
Registered: Feb 2017
Posts: 52 |
Thanks! |
| |
Krill
Registered: Apr 2002
Posts: 3098 |
Some more WIP results. :)

Spindle-Code:
CPU% ZX0 TS WIN
100 7380 7002 ZX0
90 6580 6770 TS
80 5120 5425 TS
70 4668 4722 TS
60 4117 4539 TS
50 3378 3562 TS
40 2782 3225 TS
30 2056 2564 TS
20 1321 1756 TS
10 603 817 TS
Spindle-Graphics:
CPU% ZX0 TS WIN
100 9461 8618 ZX0
90 8450 8618 TS
80 6520 6173 ZX0
70 5861 5440 ZX0
60 5259 5259 TIE
50 4288 4396 TS
40 3524 3868 TS
30 2552 3033 TS
20 1687 2019 TS
10 778 952 TS Remarkably, TSCrunch wins practically all real-world scenarios with the former benchmark, and most (again) in the latter. |
| |
Burglar
Registered: Dec 2004
Posts: 1137 |
should've been called tonycrunch ;) |
| |
tonysavon
Registered: Apr 2014
Posts: 27 |
Quote: Some more WIP results. :)
Spindle-Code:
CPU% ZX0 TS WIN
100 7380 7002 ZX0
90 6580 6770 TS
80 5120 5425 TS
70 4668 4722 TS
60 4117 4539 TS
50 3378 3562 TS
40 2782 3225 TS
30 2056 2564 TS
20 1321 1756 TS
10 603 817 TS
Spindle-Graphics:
CPU% ZX0 TS WIN
100 9461 8618 ZX0
90 8450 8618 TS
80 6520 6173 ZX0
70 5861 5440 ZX0
60 5259 5259 TIE
50 4288 4396 TS
40 3524 3868 TS
30 2552 3033 TS
20 1687 2019 TS
10 778 952 TS Remarkably, TSCrunch wins practically all real-world scenarios with the former benchmark, and most (again) in the latter.
Thanks for putting some time on these tests, krill. Happy to see TSCrunch being an option for fast decrunching in productions where speed is pivotal. I guess you can read these results also the other way around, like if you need a lot of CPU time for your parts but you still want to be able to perform some loading in the background, guaranteeing a certain throughput, then this is a viable option. Animations spring to mind. Of course if you want to ammass as much data as possible on a floppy side, zx0 remains the goat. Such a neat cruncher it is! |
| |
Krill
Registered: Apr 2002
Posts: 3098 |
Quoting tonysavonif you need a lot of CPU time for your parts but you still want to be able to perform some loading in the background, guaranteeing a certain throughput, then this is a viable option. Animations spring to mind. Still not entirely convinced that media data should be packed with general-purpose non-lossy compression.
If anything, this would be some kind of first stage of the decoder, which would then perform more data shuffling until output.
Seems like this kind of thing should be integrated in a custom codec, which would also use the loader's pollblock and getblock calls when loading. |
| |
tonysavon
Registered: Apr 2014
Posts: 27 |
Quote: Quoting tonysavonif you need a lot of CPU time for your parts but you still want to be able to perform some loading in the background, guaranteeing a certain throughput, then this is a viable option. Animations spring to mind. Still not entirely convinced that media data should be packed with general-purpose non-lossy compression.
If anything, this would be some kind of first stage of the decoder, which would then perform more data shuffling until output.
Seems like this kind of thing should be integrated in a custom codec, which would also use the loader's pollblock and getblock calls when loading.
Well, sometimes you must do both. Speaking only for my parts and my games here, but I usually do Video animations with Vector Quantisation plus delta coding. So you basically end up with a codebook (typically a charset), and this is the lossy part, and deltas for the position of the char data on screen. Now, that, in itself, is a bitstream that can be crunched but must be crunched losslessly. That data you might want to stream from disk, but you have to be really fast, and this is where a fast decruncher helps, especially if you must guarantee a certain throughput to always have the next delta-encoded video frame in ram when the frame counter ticks.
Same for audio, really, I usually do vector quantisation on a fixed audio frame: You keep the codebooks in ram, stream the payload from disk or from wherever you want to do it and that's it. Maybe you refresh the codebook every now and then for very long samples. If you choose a 8-window for audio, then the sample is compressed ~8x PLUS whatever the Cruncher gives you for the payload on top of it. And again, there's not much rastertime left if you are decoding the lossy part and playing the digi, so the faster the loader+decruncher, the higher you can go for playing frequency.
So you are right, one uses a two-stage decoder but the second stage must be lossless, fast, and (now) integrated with your loader :-). |
| |
Krill
Registered: Apr 2002
Posts: 3098 |
Quoting tonysavon[...] and this is where a fast decruncher helps, especially if you must guarantee a certain throughput to always have the next delta-encoded video frame in ram when the frame counter ticks.
Same for audio [...] I see that part of the codec may well be non-lossy. :) Just meant that a tightly-coupled integration of decompression and further decoding seems more performant than two separate stages.
But that receive-input-in-time guarantee isn't required in a real-time streaming setup if the codec is aware of eventual delayed input.
The decoder could skip over stale frames (audio or video) already before the decompression stage, if that's deemed better than simply stalling. |
| |
tonysavon
Registered: Apr 2014
Posts: 27 |
Well that would be great and make things much more streamlined on the demo coder side. To offer that as a capability from the loader would be great, but inevitably it would tie you to a specific compression schema, while coders can probably want to experiment on their own with different approaches (and for this having the loader and the codec decoupled is the best option, really). For instance, for petscii animations you don't need codebooks at all and if you have an LZ search window that is longer than 1kb, basically your everyday cruncher becomes the quickest (to implement) video encoder you can think of, with some minor modification (basically matches happen in a circular buffer rather than in plain memory). Je t'aime mon Monstre was done like that (even if it did not stream from disk but from memory). Basically "just" an endless decruncher that would use previous 1000 bytes to decode (or predict, in compression language) the following 1000. Each of them being a video frame.
Je t'aime mon Monstre
But if you had to hardwire a codec I think VQ + delta would be amazing and address a wide range of effects. Also it would not be that difficult to implement on the loader side, it would basically need to loadUncompressed the codecs and then stream the delta. Not difficult for someone who can code fasloaders, but me... I wouldn't know where to start from :-P |
| |
Krill
Registered: Apr 2002
Posts: 3098 |
For all of that, all you need is basically an exposed pollblock call, which would return "try again later" or "block with index #N is ready to download", plus a getblock call which would receive that block and put it to the desired location, no? =)
(Bonus: a skipblock call that would be called if the block is deemed stale, and just discards it without transferring.) |
| |
tonysavon
Registered: Apr 2014
Posts: 27 |
Quote: For all of that, all you need is basically an exposed pollblock call, which would return "try again later" or "block with index #N is ready to download", plus a getblock call which would receive that block and put it to the desired location, no? =)
(Bonus: a skipblock call that would be called if the block is deemed stale, and just discards it without transferring.)
Sounds like a plan!!! :-) |
| |
Krill
Registered: Apr 2002
Posts: 3098 |
Quoting tonysavonSounds like a plan!!! :-) Yeah, well, such a poll-block API existed in earlier versions, but nobody ever really used it. So it was uninvented. Can be re-added any time, of course, should anyone need it. |
| |
tonysavon
Registered: Apr 2014
Posts: 27 |
OK, I think I came up with a simple way to increase compression rate sensibly without affecting the decrunching speed (too much). I just did some preliminary tests and it seems to work nicely, but the decruncher code becomes a bit too large for my liking, at $e8 bytes for the inplace decruncher. I'll hammer it a bit more and see where this takes me, but if throughput stays roughly the same and compression rate increases consistently then it should perform much better in krill's loader. Let's see. thanks for all your help! |
| |
Krill
Registered: Apr 2002
Posts: 3098 |
Quoting tonysavonbut the decruncher code becomes a bit too large for my liking More than $30 bytes more than the earlier version? :)
Because the loader with TS-decruncher is $01d0 bytes currently. |
| |
tonysavon
Registered: Apr 2014
Posts: 27 |
Quote: Quoting tonysavonbut the decruncher code becomes a bit too large for my liking More than $30 bytes more than the earlier version? :)
Because the loader with TS-decruncher is $01d0 bytes currently.
yes, unfortunately. $33 bytes.
Are you using the inplace or not inplace version, btw?
Previous version was
$95 bytes, now $c8 for non-INPLACE decruncher
$b0 bytes, now $ee for the INPLACE decruncher
This is for the versions optimised for speed though, and I can save $10 bytes disabling speed optimisations, but that would be a bit pointless :-)
I must shuffle the code a bit more, but it'll be worth it :-) |
| |
Krill
Registered: Apr 2002
Posts: 3098 |
Using in-place version, of course. =) |
| |
tonysavon
Registered: Apr 2014
Posts: 27 |
Quote: Using in-place version, of course. =)
Figured :-P
Ok, I'll make it work within tomorrow for sure! |
| |
tonysavon
Registered: Apr 2014
Posts: 27 |
Version 1.2 is now available, which adds inplace decrunching and improves a bit on everything.
TSCrunch 1.2 |
