| |
lft
Registered: Jul 2007
Posts: 369 |
New VSP discovery
First off, this is what we already knew: VSP causes the VIC chip to briefly
place a logically undefined value on the DRAM address lines during the
halfcycle following the write to d011. If the undefined value coincides with
the RAS signal, every memory cell with an xxx7 or xxxf address is at risk of
getting corrupted. The relative timing of the undefined value and RAS depends
on several factors including temperature.
We also knew that the undefined value could be delayed slightly if VSP was
triggered by setting the DEN bit instead of modifying YSCROLL. This was enough
to avoid a crash on some machines.
I wanted to investigate whether there were other ways of controlling the timing
of the undefined value. Based on a combination of educated guesswork, luck and
plenty of trial-and-error, I could observe the following: The timing depends on
the specific 3-bit value that is written to YSCROLL, as well as the 3-bit value
that was stored in YSCROLL previously.
This means that we can trigger VSP using one of 56 methods (eight different
YSCROLL values for various rasterlines, seven non-matching YSCROLL values to
switch from), each with slightly different timing.
Using the techniques from my Safe VSP demo, I created a tool that would trigger
VSP many times, check if memory got corrupted, and keep track of the number of
crashes caused by each of the 56 methods. I then looked for a pattern in these
statistics.
Intriguingly, if I arranged the 56 crash counters in a grid with the vertical
axis corresponding to the rasterline and the horizontal axis corresponding to
the exclusive-or between the rasterline and the dummy value that was stored in
d011 prior to the VSP, then the crashes would tend to occur only in a subset of
the columns. When my crash prone c64 is powered on, the VIC chip is cold, and
there are no crashes. Within a minute, crashes start to appear in column 7
(meaning that all three bits of YSCROLL were flipped). As the chip heats up,
more crashes begin to appear in columns 3, 5 and 6 (two bits flipped). After
several more minutes, crashes show up also in columns 1, 2 and finally 4 (a
single bit flipped), but by this time, there are no longer any crashes in
columns 5, 6 or 7. Finally, when the VIC chip has reached a stable working
temperature, my machine no longer crashes.
This is what it might look like four minutes after power-on:

Now, let me stress that I only have one VSP-crashing c64, and these results
might not carry over to other machines. I hope they do, though. I would very
much like you (yes, you!) to run VSP Lab (described below) on your crash prone
machines and report what happens.
Is this useful? Short answer: Yes, very. But it hinges on whether the behaviour
of my c64 is typical. Even without the mentioned regularity in the columns, it
would be possible to find a few safe combinations for a given machine and a
given temperature. But the regularity makes it so much more practical and also
easier to explain to all C64 users, not just coders.
Let's refer to the seven columns as "VSP channels". For a given machine at a
given temperature, some of these channels are safe, and possibly some of them
are unsafe. It takes about 5-10 minutes for the VIC chip to reach its working
temperature. If you know that e.g. VSP channel #5 is safe on your machine, and
you can somehow tell a demo or game to use that specific channel, then VSP
won't crash.
My measurement tool evolved into a program called VSP Lab, depicted above,
which you can use to find out which VSP channels are safe to use on your
machine. It triggers a lot of VSP operations and visualises the crashes in a
grid, where each column corresponds to a VSP channel. Remember that a cold and
a hot VIC behave differently, so don't trust the measurements until about ten
minutes after power-on. You can reset the grid highlights using F1 to see if
channels which were unsafe before have become safe.
Demos and games could prompt the user for a VSP channel to use, or try to
determine it automatically using the same technique that VSP Lab is based on.
From a coding point of view, all you then have to do in order to implement
crash-free VSP, is to prepare the value X that you'll write to d011 to trigger
VSP, and the value Y which is X ^ vsp_channel. Then, on the rasterline where
you want to do VSP, you just wait until the time is right and do:
sty $d011
stx $d011
On the VSP Lab disk image, there's a small demo effect that you can run. It
will ask you for a VSP channel to use, and if you give it a safe number, it
should not crash.
This technique is so simple and non-intrusive that it's quite feasible to patch
existing games and demos, VSP-fixing them.
Also, this discovery explains the old wisdom that if you attempt VSP more than
once per frame, the routine will be more likely to crash. Here's why: In a demo
effect, you typically perform VSP on a fixed rasterline, so the value you write
to d011 will be constant. It is reasonable to assume that the old value of
YSCROLL will also be constant. Therefore, a given VSP effect will consistently
end up in the same VSP channel. On a machine with N safe VSP channels, the
probability of survival is therefore p = N / 7. If you do VSP on two different
rasterlines, each VSP will likewise end up in a channel, but not necessarily
the same one. The probability that both end up in a safe channel is p*p. If we
assume that most crash prone machines have at least one safe channel, we have
0 < p < 1 and therefore p*p < p. Q.E.D. To verify this, I patched vice to
report the channel every time VSP was performed. Sure enough, VSP&IK+
consistently uses VSP channel 1, as does Royal Arte. Krestage 3 uses VSP
channel 2. The intro of Tequila Sunrise, which performs VSP twice per frame,
uses VSP channels 1 and 3, and so does Safe VSP.
Finally, I will attempt to explain the observed behaviour at the electronical
level. Suppose each bit of YSCROLL is continually compared to the corresponding
bit in the Y raster counter, using XOR gates. The outputs of the XOR gates are
routed to a triple-input NOR gate, the output of which is therefore high if and
only if the three bits match. A triple-input NOR gate in NMOS would consist of
a pull-up resistor and three pull-down transistors. But the output of the NOR
gate is not a perfect boolean signal, because the transistors are not ideal.
When they are closed, they act like small-valued resistors, pulling the output
towards -- but not all the way down to -- ground potential. When YSCROLL
differs from the raster position by three bits, all three transistors
contribute, and the output reaches a low voltage. When the difference is two
bits, only two transistors pull, so the output voltage is slightly higher. For
a one-bit difference, the voltage is even higher (but still a logic zero, of
course). When we trigger VSP, all transistors stop pulling the voltage down,
and because of the resistor, the output voltage will begin to rise. But the
time it needs in order to rise to a logic one depends on the voltage at which
it begins. Thus, the more bits that change in YSCROLL, the longer it takes
until the match signal is asserted.
I have a fair amount of confidence in this theory, but need more data to
confirm it. And, once again, this is only of practical use if the average crash
prone machine has safe channels, like mine does. So please check your
equipment! I'm looking forward to your reports. |
|
| |
Perplex
Registered: Feb 2009
Posts: 255 |
Very interesting!
I've run VSP Lab on my C64C for about 50 minutes now, and my results are pretty much exactly as you describe them on your machine: no crashes during the first few minutes, then crashes starts in channel 7, then channel 3, 5 and 6, and finally in channel 1, 2 and 4 after about 17 minutes. At 20 minutes, I cleared the highlights, and now another 30 minutes after that I only have new crashes in channels 1, 2 and 4.
I don't know if it has any significance, but in the last 30 minutes, channel 1 only has crashes in line 6, and no channels have crashes in line 4.
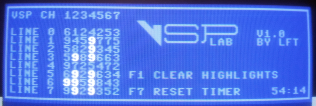 |
| |
Shadow
Account closed
Registered: Apr 2002
Posts: 355 |
First of all, thanks to lft for continuing to investigate the VSP issue - this is some very interesting finds.
I have run the VSP-Lab on my crash-prone C64 and here are the results.
I started with a cold, machine and for the first 5 minutes or so, I had no crashes at all.
Here's a the status after 16 minutes running:
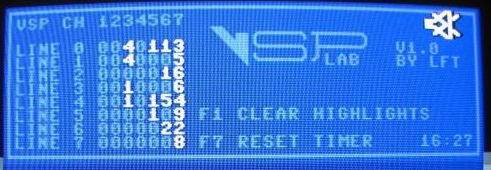
I now assumed "working temperature" was reached, and did a reset of highlights/time and let it run for another 16 minutes (32 total):

So on my machine it seems like the singe-bit-channels (1,2,4) are safe somehow. I'll run more tests tomorrow and see if this still holds true.
Anyway, I tried running the demo after that, choose channel 1 and it ran without a hitch!
Once again, fantastic job lft! |
| |
Shadow
Account closed
Registered: Apr 2002
Posts: 355 |
Well, scratch that single-bit-channels are safe on my machine! :(
Running a new test now, and after 30 minutes I have crashes on all channels. Will let it run for a while more and then do a clear highlights and see if it has stabilized to ONLY crash on the single-bit channels (as both lft and perplex machines seem to do). |
| |
Perplex
Registered: Feb 2009
Posts: 255 |
Update: after running for about an hour and a half, I reset the highlights and timer, then let it run for another hour or so, and there were NO crashes at all! It looks like my C64C is indeed VSP-safe when properly warmed up. I will now turn it on and let it stay at the basic prompt for 90 minutes before starting VSP Lab, and report here what happens then. |
| |
hedning
Registered: Mar 2009
Posts: 4732 |
My c64c (The gubbdata compo machine) was turned on by this experiment, and just as the rest of you, it had no crashed the first 5 minutes or so. After some chaotic 25 minutes it looks like this:

After that I resetted time and cleared the highlights and run for another 25 minutes:

For a long time it looked like channel 1 and 2 were safe, but after 15 minutes (40 minutes totally) they also got their amount of crashes. After 25 minutes (50 totally) it looks like channel 4 (0 crashes since startup) and 7 (safe after warmup) are the safe ones on my machine, but I'll let it run for some hours today, and then unleash VSP Lab again...
(EDIT) The demo did crash directly on channel 7, though, but not on channel 4) (/EDIT) |
| |
Shadow
Account closed
Registered: Apr 2002
Posts: 355 |
OK, here are my latest results:
Power on the machine, no crashes in the first minutes.
Then after 35 minutes, we have this
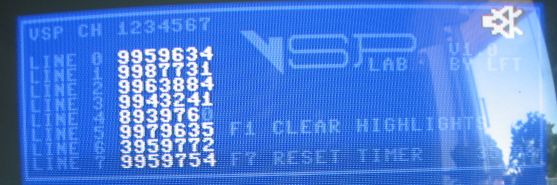
I let it run for a bit more (maybe an hour) then powercycled, and ran another 16 minutes
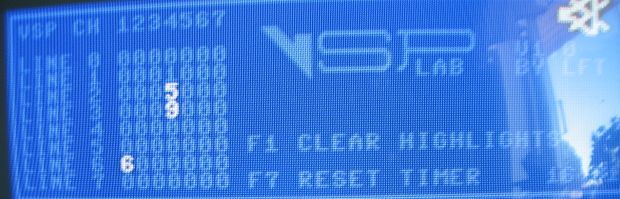
So my machine seems to have this behavior:
From first powerup (when cold) - stable for a few minutes.
The during warmup (from 5 up to 60 minutes or so) crashes on first multi-bit channels, then more towards single-bit channels.
Fully warmed up (60 minutes +) occasional crashes on single-bit channels. |
| |
hedning
Registered: Mar 2009
Posts: 4732 |
2 hours of LFT demo on channel 4 without crash (Gubbdata compo machine). Time to see how the report looks like after a 3h warmup, resetted and ran VSP Lab for 5 minutes, and wtf? Channel 4 is screwed after just one minute? Does it matter if the computer is resetted? Maybe I should restart the computer completely instead with the power switch? Did that. No errors at all for 20 minutes.
Is this interesting? Should it matter if you restart your computer or just reset it? Ergo: It seems that after being restarted completely in a warm up state my computer shows no errors at all (tried the demo, and there it died on channel 1 and 2 at least). When resetted channel 4 (that worked flawlessly for over 2 h before, running the demo) and some other channels were showing errors after just some minutes.
The most disturbing thing is that the demo still crashes even if the VSP Lab tells me there should be no crashes. And yes, lft, you may borrow this machine (and many more - I guess at least 10) for testing purposes. :) |
| |
chatGPZ
Registered: Dec 2001
Posts: 11386 |
Quote:Does it matter if the computer is resetted?
the timing/behaviour changes randomly at either reset or powercycle - making testing pretty much a gamble :)
and yes, interesting program! |
| |
hedning
Registered: Mar 2009
Posts: 4732 |
Quote:the timing/behaviour changes randomly at either reset or powercycle
Randomly? I left the computer on for 1,5h now, and got these results:

After that I reset and tried the VSP Lab three times in a row, and got similar patterns:



After that I made a powercycle, and got these results:

Resetting your machine gives not very random results at all. In this very case I got channel 3, 5, 6, and 7 without crashes four times in a row.
Making a powercycle seems to make pretty random patterns, though. For every powercycle it seems that a new pattern comes up, a pattern that will survive a reset, but not a powercycle. This needs more testing of course. Maybe it's just my machine. |
| |
chatGPZ
Registered: Dec 2001
Posts: 11386 |
Quote:Resetting your machine gives not very random results at all.
you cant prove that with a handful tests, really. make a couple of thousends of them, then come back :) if your results "prove" anything, its that powercycle and reset do different things. if it all. |
| |
hedning
Registered: Mar 2009
Posts: 4732 |
I just said that it may be a pattern, and that it might be interesting. |
| |
tlr
Registered: Sep 2003
Posts: 1790 |
@lft: Very interesting read and a good test program!
@hedning: a plain reset does very little to the die temperature but a power cycle does.
This kind of thing might even be dependent on the difference in temperature between ICs. |
| |
TPM
Registered: Jan 2004
Posts: 110 |
i do and don't understand this.. well.. i understand the basics ofcourse and i do know how IC's work, etc..
but i think it would be hard to get control by code, if temperatures and such influences are involved.
Why are you so sure, lft? Respect if you do, i like your post and test program big time anyway! |
| |
chatGPZ
Registered: Dec 2001
Posts: 11386 |
well, if you know what variables (may) depend on temperature ... you maybe can take them out of the equatation so it does no more matter. (RE: lax#$00 :=)) |
| |
tlr
Registered: Sep 2003
Posts: 1790 |
What groepaz said. Very good example! |
| |
Fungus
Registered: Sep 2002
Posts: 686 |
Nice program, I don't have any c64's to test it with anymore though. Too bad, as I would have liked to see the results...
Other than that, gremlins in the timing of c64 clocks. Maybe there can be some more research done on hw side, to maybe find a way to make the 64 power up more stable. |
| |
ChristopherJam
Registered: Aug 2004
Posts: 1409 |
My c64c + RR + RR-net has been running for weeks with only the occasional power-cycle. It's not been power-cycled today (only reset), and the ambient temperature in my apartment has been between 15 and 19 degrees for the last three or four days.
I've been running VSP Lab for 48 minutes now, and it's been showing zeros across the board the entire time. |
| |
Kabuto
Account closed
Registered: Sep 2004
Posts: 58 |
Quote:Making a powercycle seems to make pretty random patterns, though.
I think I've read the reason for that in another thread, it was like: The master clock is divived by 9 and then multipled with 4 (or the like) to get the pixel clock and this isn't jitter-free. Depending on how this pattern (repeating every 4 pixels or the like) is aligned in respect to the 1 MHz clock (repeataing every 8 pixels) this can give different outcomes. This alignment is randomly chosen when the C64 is powered on but not affected by resets. |
| |
ChristopherJam
Registered: Aug 2004
Posts: 1409 |
Ah, good point @Kabuto. I came across that issue when I was trying to do screencaps of which colours were produced by groups of three adjacent highres pixels at each of the 32 possible phase locations. I was getting consistent results when I was just resetting between tests, but as soon as I power-cycled my calibration went out the window. (so much for new colours :P)
It might be interesting to show a pair of crosshatched black & white characters onscreen ($55,aa,55,aa,55,aa,55,aa,55,aa) to see if there's any correlation between master clock phase and which channels cause errors, at least for machines that have different error behaviour between power-cycles. |
| |
ChristopherJam
Registered: Aug 2004
Posts: 1409 |
Oh, also one of my spare c64cs has apparently died altogether, but my breadbox is showing no errors on any channel despite running VSP Lab within seconds of the first time I've powered it on in over a year. |
| |
ChristopherJam
Registered: Aug 2004
Posts: 1409 |
What am I talking about, lft has already included such a pattern in the gap. edit to suggestion- keep an eye out for the phase of the red/blue bars :) |
| |
lft
Registered: Jul 2007
Posts: 369 |
Time to back up my claims with more data.
I added a logging feature to VSP Lab (VSP Lab V1.1), that counts the number of crashes
on each VSP channel for one hour and plots a histogram. One minute corresponds
to five horizontal pixels, and the start of each minute is indicated with a
small dot below the chart. There is no built-in function to save the chart to
disk, but with a monitor cartridge it's just a matter of:
S"FILENAME",8,A000,AA00
Hedning gallantly lent me five machines, which I have measured several times.
The results largely confirm my theories, but the following additional facts
have surfaced:
1. The working temperature rises quickly for approximately ten minutes, then it
keeps rising slowly for at least an hour, probably more. This can be seen in
the charts where the machine was started cold: Changes in the set of safe
channels are close together towards the left end of the graph and more
drawn out towards the right.
The machine also appears to cool down rather quickly when you switch off the
power.
2. At power-on, the machine selects randomly among a handful of "behaviours".
It will stick with this behaviour across resets (neither the VIC chip, the RAM
nor the system clock generator are connected to the reset signal), but can
change if you do a power-cycle. Remember that the 1541 Ultimate reset button by
default also resets the emulated 1541, so there's no need to power-cycle a C64
unless you're going to plug/unplug hardware.
Here are the logs from two of Hedning's machines that we can call H4 (serial
number 491239) and H5 (311520). They are not displayed in chronological order.
Rather, I have identified two behaviours for each machine, and sorted the
charts according to these.
H5, behaviour 1:
Cold start:


Warm start:
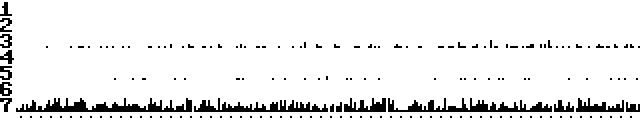


H5, behaviour 2:
Cold start:

Warm start:



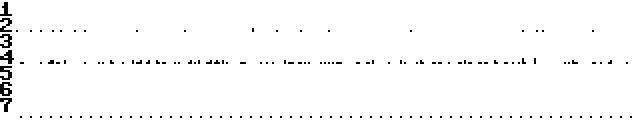
The last one of those is possibly a third behaviour for this machine.
H4, behaviour 1:
Cold start:

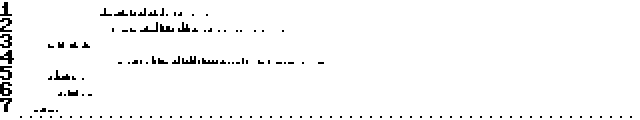
Warm start:


To quote Devia in a different thread:
"in my experience a c64 running VSP code with no problems, might fail after a
power cycle while continuing to run stable between resets."
Clearly, behaviour 1 of machine H4 (once it's warmed up) is precisely such a
stable mode, but a power-cycle might drop us into:
H4, behaviour 2:
Cold start:
(not captured)
Warm start:

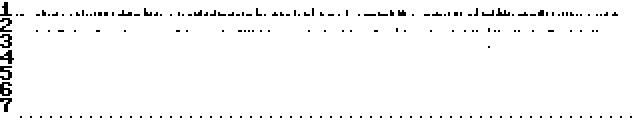
Both machines H4 and H5 use the new VIC chip and the short motherboard.
However, Soundemon has reported VSP crashes on a 5-luma VIC in a breadbox.
Five bits are flipping as the address bus goes from $ff to $07. Three major
factors contribute to the timing of the five bit transitions with respect to
the RAS signal: The power-on behaviour, the number of set bits in the VSP
channel number, and the temperature. Apart from this, the rasterline and the
specific VSP channel will also affect the timing due to process variations, but
this is less pronounced.
The five bits don't necessarily flip at the same time. The relative timing of
the bit-flips appears to be stable for a given machine. If any of these
coincide with RAS, there is risk for a crash.
As you can see from the charts, there is a general pattern of progressing from
the 3-bit channel (7) via the 2-bit channels (3, 5, 6) to the 1-bit channels
(1, 2, 4). On channel 7, the bit-flips are late. As temperature goes up, they
get even later, and the bit-flip that coincided with RAS gets pushed out of the
critical zone. Meanwhile, if we perform VSP on channel 3, 5 or 6, the bit-flips
are a bit earlier and don't coincide with RAS. As temperature goes up, a
bit-flip gets pushed into the critical zone. Sometimes, like in the first two
charts, we see crashes disappearing from channels 1, 2 and 4 only to appear
later in channel 7. What we see is the next of the five bit transitions
approaching RAS.
Depending on the relative timing of the five bit-flips, there could be machines
which consistently crash on all channels. If you have such a machine, I'm
afraid these techniques will not help you.
Otherwise, the practical method for avoiding VSP crashes goes something like
this: Power on the machine. Run VSP Lab for ten minutes and look at the log.
Note which channels are unsafe; try to predict the next thing that will happen,
based on the ordering described above. E.g. if some 1-bit channels recently
became unsafe, then the remaining 1-bit channels might also become unsafe
within the next hours. On the other hand, if some 1-bit channels recently
became safe, then you should be more worried about channel 7 becoming unsafe.
Note down what VSP channel is safe, and select this channel when watching demos
or playing games. Don't power-cycle the machine, but use the reset button!
Every time you power-cycle, you have to do the whole procedure again, running
VSP Lab and looking at the log, although you won't have to wait the full ten
minutes if the machine is already warm.
If your machine crashes on all channels when warm, but not when cold, then you
might be able to fix it by mounting a fan over one of the ports at the back of
the machine.
If a machine survives several hours of VSP Lab without a single crash, and you
can repeat this several times with power-cycles in between, then you can be
fairly confident that the machine will never crash on VSP.
I propose the following:
1. Demo/game coders should include a VSP channel selector (if VSP is used). We
should add options in Vice to crash on a subset of the channels, to help with
debugging.
2. For home use, a machine only needs to be safe on one channel. This will
finally allow many people to watch the latest demos on real hardware.
3. Compo machines should be safe on all channels. This can be verified using
VSP Lab.
The great benefit is #2, which requires some effort on the part of the coders
(#1). A side-benefit of VSP Lab is that party organisers now have an easy way
to verify #3. |
| |
hedning
Registered: Mar 2009
Posts: 4732 |
Very interesting! Thanx to lft I now know that I have a VSP-safe C64C ready for the BFP and future Gubbdata compos. ;) |
| |
chatGPZ
Registered: Dec 2001
Posts: 11386 |
Quote:Demo/game coders should include a VSP channel selector (if VSP is used).
i honestly doubt anyone would bother. while the whole issue is very interesting by itself - i really dont see how it is a major problem in practise.
being able to find vsp-crashing machines is nice though. and then using the good old hammer method to fix them =P |
| |
ChristopherJam
Registered: Aug 2004
Posts: 1409 |
@lft, is there a difference in colour phase displayed in the $3fff area when H5 is exhibiting behaviour 1 to when it is exhibiting behaviour 2? |
| |
soci
Registered: Sep 2003
Posts: 480 |
Now that we have this nice testing tool it would be interesting to see what happens when RAS and other signals are manipulated in hardware ;) |
| |
Frantic
Registered: Mar 2003
Posts: 1648 |
Quote: Very interesting! Thanx to lft I now know that I have a VSP-safe C64C ready for the BFP and future Gubbdata compos. ;)
Classy! :) |
| |
lft
Registered: Jul 2007
Posts: 369 |
Quoting ChristopherJam@lft, is there a difference in colour phase displayed in the $3fff area when H5 is exhibiting behaviour 1 to when it is exhibiting behaviour 2?
To some extent.
I increased the contrast by changing to white background, then wrote down the colour carrier phase in terms of the order of the artefact colour bars (magenta/cyan, and how much of the first one is visible), along with the observed behaviour. I did this about ten times, and for some phases I would always see the same behaviour, whereas for other phases the behaviour was unpredictable. With such a low number of samples, the predictable ones might of course in fact be unpredictable. |
| |
Zer0-X
Account closed
Registered: Aug 2008
Posts: 78 |

Despite taking numerous screenshots of the clock phases still ended up with one gap. But 16 powerup states can be identified for the clocks. |
| |
WVL
Registered: Mar 2002
Posts: 902 |
Interesting screenshots (is it really called that?). I wonder if there's a simple way to reliably detect what powerup-state you're in. I know you can't determine with software (or is it?) and you would need at least some extra hardware. I can imagine some simple piece of addon electronics that measure the powerup state and put the result on some register that the ROM can read and display on the screen on powerup.
Like
**** commodore 64 basic v2 ****
64K ram system 38911 basic bytes free
powerup state : 12
ready.
Then the user could decide to powerup again to get to a stable state for his/her machine. |
| |
chatGPZ
Registered: Dec 2001
Posts: 11386 |
at this point i would want to recheck if replacing the ram and preventing the VIC from writing to it wouldnt completely fix the problem.... :) |
| |
tlr
Registered: Sep 2003
Posts: 1790 |
Quoting WVLI can imagine some simple piece of addon electronics that measure the powerup state and put the result on some register that the ROM can read and display on the screen on powerup.
...
Then the user could decide to powerup again to get to a stable state for his/her machine.
Wouldn't it be better to make some electronics locking the phase to the vic-II? |
| |
Skate
Registered: Jul 2003
Posts: 494 |
after writing this comment, i noticed similar comments are already written. so, i post it like "+1".
this whole thing is very interesting but test results show me that what we really need is a VSP safe machine, not a safe VSP routine. i believe same machine may give different test results with different power supplies or even different places with different electricity infrastructure.
now, thanks to lft, we have a great VSP test utility. now some hardware gurus should build some easy to implement hardware fix and we should all apply this patch. amiga guys do many hw patches, right? we can do as well. |
| |
Kabuto
Account closed
Registered: Sep 2004
Posts: 58 |
I agree that the ideal solution would be a hardware modification since this bug can also be triggered by non-VSP code that accidentally creates a VSP condition. Odds are pretty low (re-enabling display or changing vscroll without timing will trigger VSP with a probability of about 0.2%, and then, according to the plots, up to 2% of those might actually crash) but even simple basic games that just modify $D011 for a cheap screen shake effect can crash. |
| |
tlr
Registered: Sep 2003
Posts: 1790 |
Sure, it would be nice to have fixed but there are many other machine/temp dependent stuff that is flaky (e.g LAX, ANE). Should we fix those too?
The question is obviously retorical. The difference is that VSP is commonly used.
Still it's definately on the border of what should be considered safe to use. It seems to me that LAX #$00 is safer than vsp for instance.
I'd rather we found a safe/safer way to use the unmodified hardware, which I believe is exactly what lft is trying to do. |
| |
HCL
Registered: Feb 2003
Posts: 728 |
Hmm.. My c64 and c128 ran the test for an hour+ at BFP, but they were both clean (!). This is puzzeling since i know that at least the c128 was a bitch to code d011-stuff on in the early 90's, and that was the only thing i wanted to do back then :P. |
| |
Martin Piper
Registered: Nov 2007
Posts: 722 |
Replacing DRAM with SRAM should fix the issue. It might need some extra logic circuitry. |
| |
algorithm
Registered: May 2002
Posts: 705 |
Thats a bit overkill however |
| |
chatGPZ
Registered: Dec 2001
Posts: 11386 |
and zero-x (i think) tried it - doesnt fix it at all (i guess you must disconnect/prevent the VIC from writing to it too) |
| |
Zer0-X
Account closed
Registered: Aug 2008
Posts: 78 |
Quote: and zero-x (i think) tried it - doesnt fix it at all (i guess you must disconnect/prevent the VIC from writing to it too)
Nope, haven't tried it. Tempting tho. |
| |
chatGPZ
Registered: Dec 2001
Posts: 11386 |
mmmh then who was it.... i somehow remember someone tried what happens.... *shrug* |
| |
tokra
Registered: Jun 2011
Posts: 9 |
I think the difference between using VSP and using illegal opcodes is that VSP should work according to the specification while with illegal opcodes you are just lucky that they work despite the specification.
So, even though the failure rate may just be 2% of 0.2% in standard cases (1 in 25.000) this can be considered a hardware-defect.
On the other hand I could imagine if Commodore engineers in 1982 knew about this error and had presented it to Jack Tramiel he would have just shrugged it off as "works good enough" and gone to production anyway.
Now, 30 years later the situation is different. There are demos that use this effect and a lot of machines that crash when it is used (my C128D included). So I for one would very much welcome a hardware-fix that rectifies this issue at last. |
| |
WVL
Registered: Mar 2002
Posts: 902 |
I can only agree with this. While VSP was never a 'feature', changing the value of $d011 surely always was intended. It can only be described as a defect that changing $d011 (for whatever your purpose is) can crash some machines. |
| |
Oswald
Registered: Apr 2002
Posts: 5094 |
I would be glad to see the specification which says VSP should work. Truth is its just as a lucky side effect as illegal opcodes, and under normal circumstances no1 would try to manipulate d011 the VSP way, just like normally no1 would try to use non specified opcodes.
Anyway, emulators cope with VSP well since ages, and anyone can buy as much c64 as much he can until he finds a VSP safe one, so VSP crasing is rather an artifical problem in my eyes. Or in other words, wanking nerds whining over 30 year old HW problems. |
| |
tokra
Registered: Jun 2011
Posts: 9 |
Writing to $d011 should work. Even if you do it just once chances are your machine will crash. While these chances are VERY low, one might discuss if those are acceptable from an engineering standpoint.
What are normal circumstances? Was sprite-multiplexing intended? Or FLI? Or opening the borders?
Sure one could just use emulators or a different machine or one could just say "don't use VSP". But "wanking and whining" about these and similar issues 30 years later is half of the fun. Exploring the extreme limits of this machine is what the whole scene is about, isn't it? So if someone were to present a hardware-fix for this issue as part of a say a Wild-Compo it would get my thumbs up just as much as the latest demo that uses another quirk of the VIC-chip. |
| |
Oswald
Registered: Apr 2002
Posts: 5094 |
I think sprite multiplexing was definitly intended, while designing the chip, hence the TI99 did it in HW long before, which the designers had a look at before starting :)
I agree with the 2nd part fully. And have to admit I agree with the first too, if one write may crash the machine then its definitly a bug in the design. |
| |
enthusi
Registered: May 2004
Posts: 677 |
Independent on the idea that d011-fiddling should never crash a machine, I consider hw-fixes super-lame.
Let's not get where all the other dead scenes went with their numerous hd-updates/fixes/revisions.
If it cant be handled by all plain c64s, then it sucks.
People did not know, now they do.
Also there ARE work-arrounds available now to be considered a new challenge. |
| |
tlr
Registered: Sep 2003
Posts: 1790 |
enthusi is spot on with his comment. +1
If you do use a feature like VSP or even a simpler one like the exact pixel timing of a color split then you need to consider what happens on different machines and try to avoid it manifesting in the final result. |
| |
tokra
Registered: Jun 2011
Posts: 9 |
I can see both points of view. The software should have avoided this issue in the first place. Since the unwanted effect shows so seldomly, it was not confirmed to be an actual underlying hardware-design-issue before lft found out the reason some months ago.
So while I fully agree that from now on coders should take this into account when doing VSP-effects, this still leaves about 30 years of existing software that might crash your computer if it changes $d011 even just once. Fixing all this software would certainly be very cumbersome, if even possible at all. So, if it is possible to create a hardware-fix for this issue, why not go for it? |
| |
chatGPZ
Registered: Dec 2001
Posts: 11386 |
Quote:Fixing all this software would certainly be very cumbersome, if even possible at all.
finally a good use for all these hax0rcrax0rs =P |
| |
Martin Piper
Registered: Nov 2007
Posts: 722 |
Quote: mmmh then who was it.... i somehow remember someone tried what happens.... *shrug*
Someone did it on the speccy
http://bitcycle.org/retro/spectrum/SRAM_replacement/ |
| |
Zer0-X
Account closed
Registered: Aug 2008
Posts: 78 |
In theory it should work the same as with speccy.
RAS & CAS still having control over the address loading and PLA taking care of keeping RAM off the bus when accessing IO, etc.
What annoys me is the need for a single damn inverter for the RAS to strobe half of the address to the buffering latch. With a single 64k SRAM chip one could do it using a single extra TTL chip if the RAS didn't have to be inverted. With 2x 32k SRAMs (what I happen to have) yet one more TTL chip needs to be added. The more chips, the more propagation delay, the more problems. Tho it would be for testing. |
| |
Zer0-X
Account closed
Registered: Aug 2008
Posts: 78 |
Hnngh, stupid me... Ofcourse the latch keeps storing the address and "locks" it in when RAS activate.
Also found out some german guy had already SRAM-modded his C64 two years ago. Tho I doubt he did any VSP testing, which I'm pretty sure would work just fine with the setup. |
